Published
Author Egon Willighagen
I just want to drop this here. There are various ways to make BridgeDb identifier mapping files.
I just want to drop this here. There are various ways to make BridgeDb identifier mapping files.
This is my last post on blogger.com. At least, that is the plan. It has been a great 18 years. I like to thank the owners of blogger.com and Google later for providing this service. I am continuing the chem-bla-ics on a new domain: https://chem-bla-ics.linkedchemistry.info/ I, like so many others, struggle with choosing open infrastructure versus the freebie model.
Some days ago, I started added boiling points to Wikidata, referenced from Basic Laboratory and Industrial Chemicals (wikidata:Q22236188), David R. Lide’s ‘a CRC quick reference handbook’ from 1993 (well, the edition I have). But Wikidata wants pressure (wikidata:P2077) info at which the boiling point (wikidata:P2102) was measured. Rightfully so. But I had not added those yet, because it slows me and can be automated with QuickStatements.
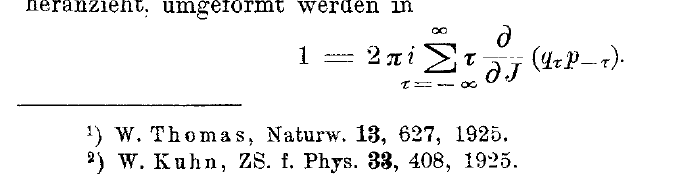
Just a quick note: I just love the level of detail Wikidata allows us to use. One of the marvels is the practices of named as, which can be used in statements for subject and objects. The notion and importance here is that things are referred to in different ways, and these properties allows us to link the interpretation with the source.
Earlier I reported about postgenomic.com , and needed some diversion from my manuscript work (could no longer think straight about the article I’m working on). So time for some reading up on new technologies. Timing was perfect, because the source code of postgenomic.com got just uploaded to SourceForge SVN.
For the past few weeks I have been working on a review article, which will contain a section with new QSAR/QSPR descriptors published in the period 2000-now.
OpenSource, OpenData and OpenStandards are not as strong in chemoinformatics as they are in bioinformatcs, where it is common knowledge that sharing is a good. Today, the JCIM published on the web an article about the Blue Obelisk movement, which promotes these three idealogies. Several open source projects participate, amongst which the CDK, Jmol, JOELib, OpenBabel, Chemical Markup Language, Bioclipse and Kalzium.
You might have read earlier posts in this blog on CMLRSS, and received a question today on how to integrate CMLRSS with blogs on blogspot.com. Now, current CMLRSS feeds are normally generated with customized scripts, often directly from a database. So, here’s my attempt to include CML in a blogspot.com blog. OpenBabel 2.0 can create good CML, for example for acetic acid: Nothing much to see, right?
Gemma Holiday’s article on CMLReact was published in the january issue of the JCIM (doi:10.1021/ci0502698), which seems to be marked as sample issue right now. She used CMLReact as data format for MACiE (see doi:10.1093/bioinformatics/bti693), a database of 100 enzyme reactions, with fully annotated reaction mechanisms, making this an remarkable and insightfull database.
Roland Krause discussed today in his blog Notes from the Biomass an interesting website: postgenomic.com . This website, still marked BETA, mines blogs in the field of genomics and extract noteworthy statistics from it: which articles are cited in those blogs. For example, the most discussed article is Kai Wang’s Gene-function wiki would let biologists pool worldwide resources in Nature.