
Published
Author Chris Armit
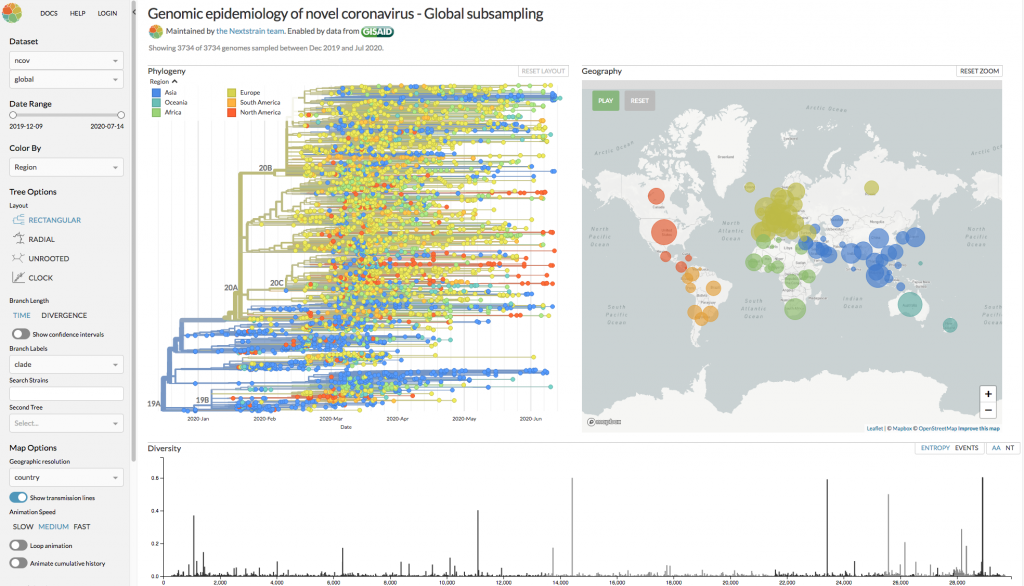
Meetings In the Time of Coronavirus: Conferences go Viral June-July usually marks peak conference season when the GigaScience team is on the road, but with the COVID-19 pandemic shutting down travel and public gatherings it has been a strangely static summer.








