
Published
Author Stephen Royle

We have a new paper out! You can access it here.
We have a new paper out! You can access it here.

I was recently an external examiner for a PhD viva in Cambridge. As we were wrapping up, I asked “if you were to do it all again, what would you do differently?”. It’s one of my stock questions and normally the candidate says “oh I’d do it so much quicker!” or something similar. However, this time I got a surprise. “I would write my thesis in LaTeX!”, was the reply. As a recent convert to LaTeX I could see where she was coming from.

I’m currently writing two manuscripts that each have a substantial data modelling component. Some of our previous papers have included computer code, but it was straightforward enough to have the code as a supplementary file or in a GitHub repo and leave it at that. Now with more substantial computation in the manuscript, I was wondering how best to describe it. How much detail is required?

Something that has driven me nuts for a while is the bug in FIJI/ImageJ when making montages of image stacks. This post is about a solution to this problem. What’s a montage? You have a stack of images and you want to array them in m rows by n columns. This is useful for showing a gallery of each frame in a movie or to separate the channels in a multichannel image.
Today I saw a tweet from Manuel Théry (an Associate Ed at Mol Biol Cell ). Which said that he heard that the Editor-in-Chief of MBoC, David Drubin shops for interesting preprints on bioRxiv to encourage the authors to submit to MBoC.

I have written previously about Journal Impact Factors (here and here). The response to these articles has been great and earlier this year I was asked to write something about JIFs and citation distributions for one of my favourite journals. I agreed and set to work. Things started off so well. A title came straight to mind.

I was interested in the analysis by Frontiers on the lack of a correlation between the rejection rate of a journal and the “impact” (as measured by the JIF). There’s a nice follow here at Science Open.

There have been calls for journals to publish the distribution of citations to the papers they publish (1 2 3). The idea is to turn the focus away from just one number – the Journal Impact Factor (JIF) – and to look at all the data. Some journals have responded by publishing the data that underlie the JIF (EMBO J, Peer J, Royal Soc, Nature Chem). It would be great if more journals did this.

A few days ago, Retraction Watch published the top ten most-cited retracted papers. I saw this post with a bar chart to visualise these citations. It didn’t quite capture what the effect (if any) a retraction has on citations. I thought I’d quickly plot this out for the number one article on the list.
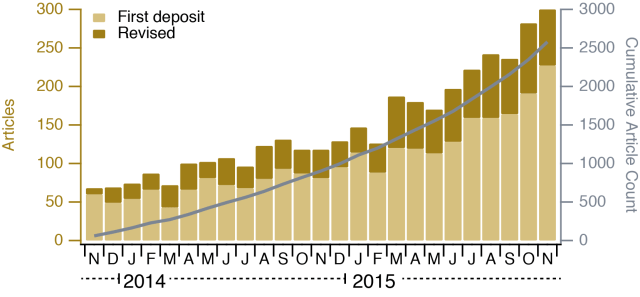
bioRxiv, the preprint server for biology, recently turned 2 years old. This seems a good point to take a look at how bioRxiv has developed over this time and to discuss any concerns sceptical people may have about using the service.