Publicado in rOpenSci - open tools for open science
Autores Eduardo Arino de la Rubia, Shannon E. Ellis, Julia Stewart Lowndes, Hope McLeod, Amelia McNamara, Michael Quinn, Elin Waring, Hao Zhu
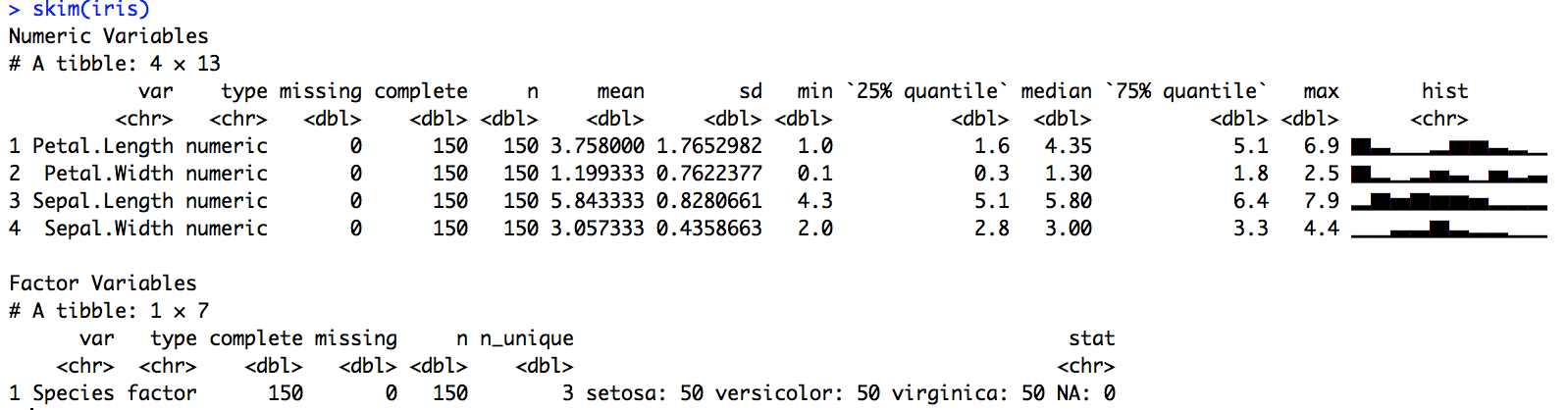
Like every R user who uses summary statistics (so, everyone), our team has to rely on some combination of summary functions beyond summary() and str(). But we found them all lacking in some way because they can be generic, they don’t always provide easy-to-operate-on data structures, and they are not pipeable. What we wanted was a frictionless approach for quickly skimming useful and tidy summary statistics as part of a pipeline.