Publicado in iPhylo
Autor Roderic Page

I've put a short note up on bioRxiv about ways to geocode nucleotide sequences in databases such as GenBank. The preprint is "Geocoding genomic databases using GBIF" https://doi.org/10.1101/469650.
I've put a short note up on bioRxiv about ways to geocode nucleotide sequences in databases such as GenBank. The preprint is "Geocoding genomic databases using GBIF" https://doi.org/10.1101/469650.
Notes on how many georeferenced DNA sequences there are in GenBank, and how many could potentially be georeferenced.
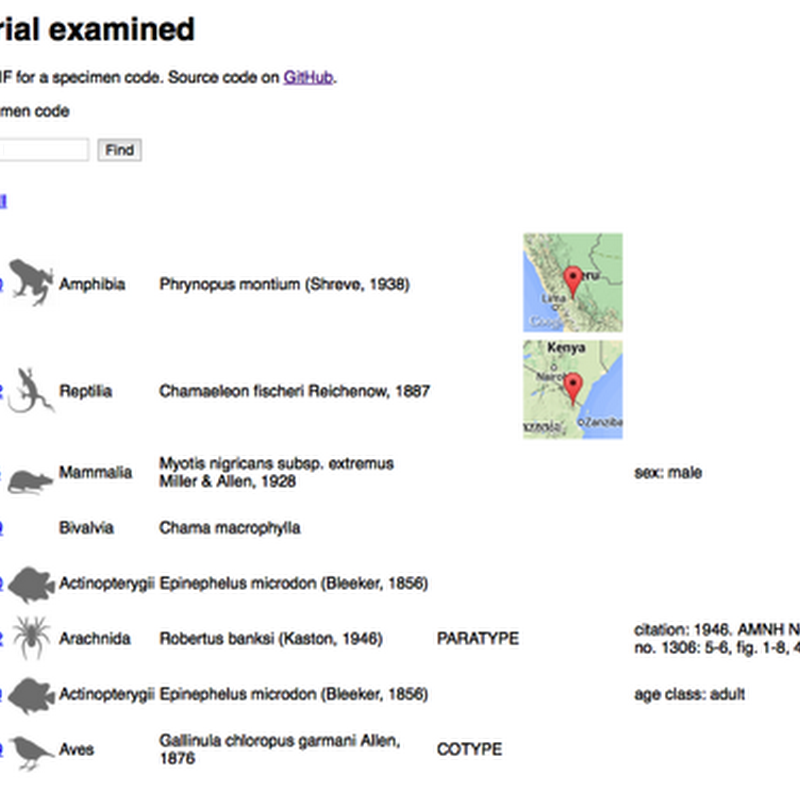
I've put together a working demo of some code I've been working on to discover GBIF records that correspond to museum specimen codes. The live demo is at http://bionames.org/~rpage/material-examined/ and code is on GitHub. To use the demo, simply paste in a specimen code (e.g., "MCZ 24351") and click Find and it will do it's best to parse the code, then go off to GBIF and see what it can find.
An undergraduate student (Aime Rankin) doing a project with me on citation and impact of museum collections came across a paper I hadn't seen before:Unfortunately the paper is behind a paywall, but here's the abstract (you can also get a PDF here):It's well worth a read. It argues that sequence databases such as Genbank are essentially the equivalent of the great natural history museums of the 19th Century. There are several ironies here.

Scott Federhen told me about a nice new feature in GenBank that he's described in a piece for NCBI News. The NCBI taxonomy database now shows a its of type material (where known), and the GenBank sequence database "knows: about types. Here's the summary:You can query for sequences from type using the query "sequence from type"[filter]. This could lead to some nice automated tools.

The following is a guest blog post by David Schindel and colleagues and is a response to the paper by Antonio Marques et al. in Science doi:10.1126/science.341.6152.1341-a.Marques, Maronna and Collins (1) rightly call on the biodiversity research community to include latitude/longitude data in database and published records of natural history specimens.
One reason I'm pursuing the theme of specimen identifiers (and identifiers in general) is the central role they play in annotating databases. To give a concrete example, I (among others) have argued for a wiki-style annotation layer on top of GenBank to capture things such as sequencing errors, updated species names, etc. Annotation is a lot easier if we have consistent identifiers for the things being annotated.
As part of my mantra that it's not about the data, it's all about the links between the data, I've started exploring matching GenBank sequences to GBIF occurrences using the specimen_voucher codes recorded in GenBank sequences. It's quickly becoming apparent that this is not going to be easy.
Last month, feeling particularly grumpy, I fired off an email to the TDWG-TAG mailing list with the subject Lobbing grenades: a challenge . Here's the email:In the context of the TDWG meeting (happening as we speak and which I'm following via Twitter, hashtag #tdwg) Joel Sachs asked me whether I had any specific data in mind that could form the basis of a discussion. So, here goes.
In an earlier post (Are names really the key to the big new biology?, I questioned Patterson et al.'s assertion in a recent TREE article (doi:10.1016/j.tree.2010.09.004) that names are key to the new biology.In this post I'm going to revisit this idea by doing a quick analysis of how many species in GenBank have "proper" scientific names, and whether the number of named species has changed over time.