Publicado in dataand.me
Autor Mara Averick
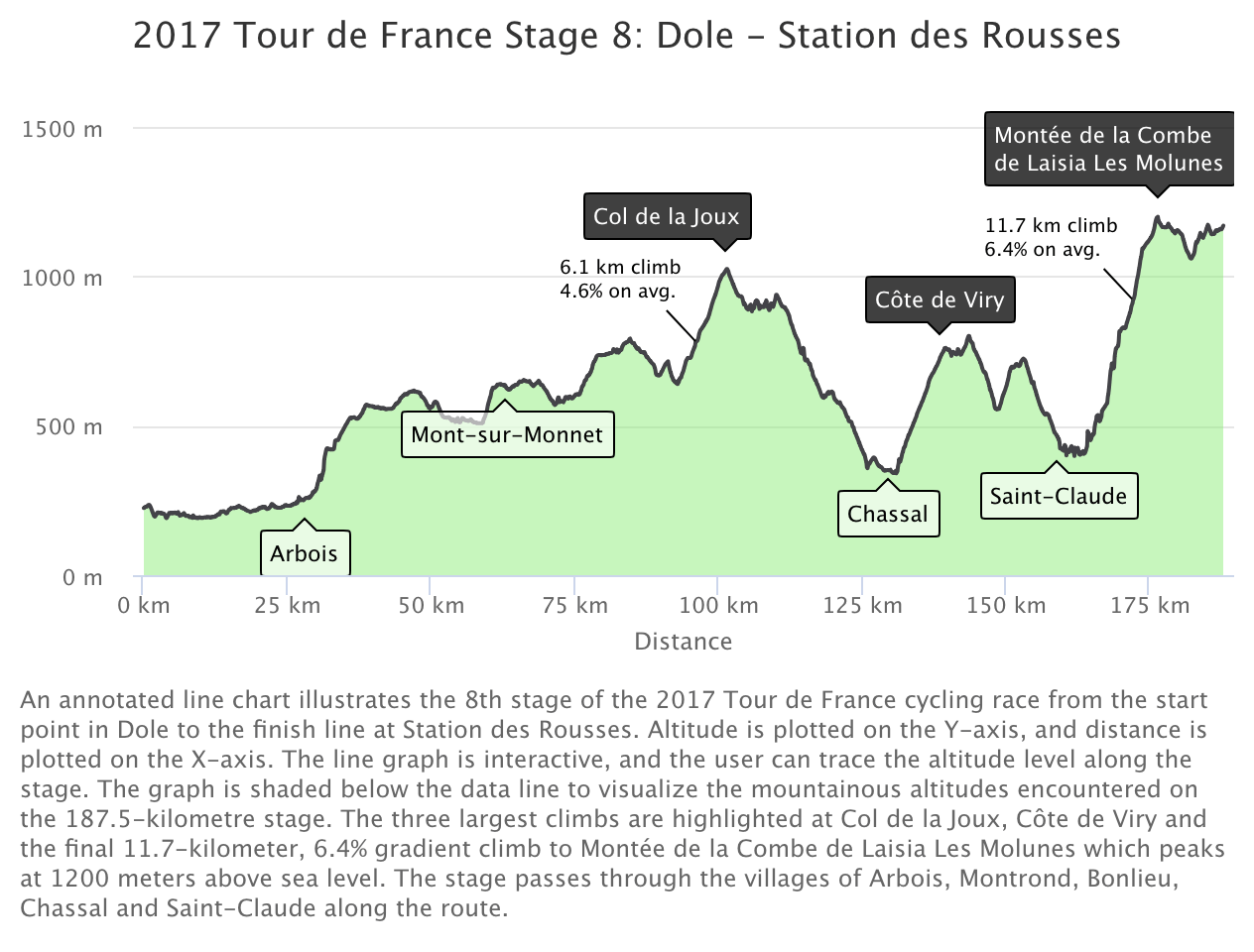
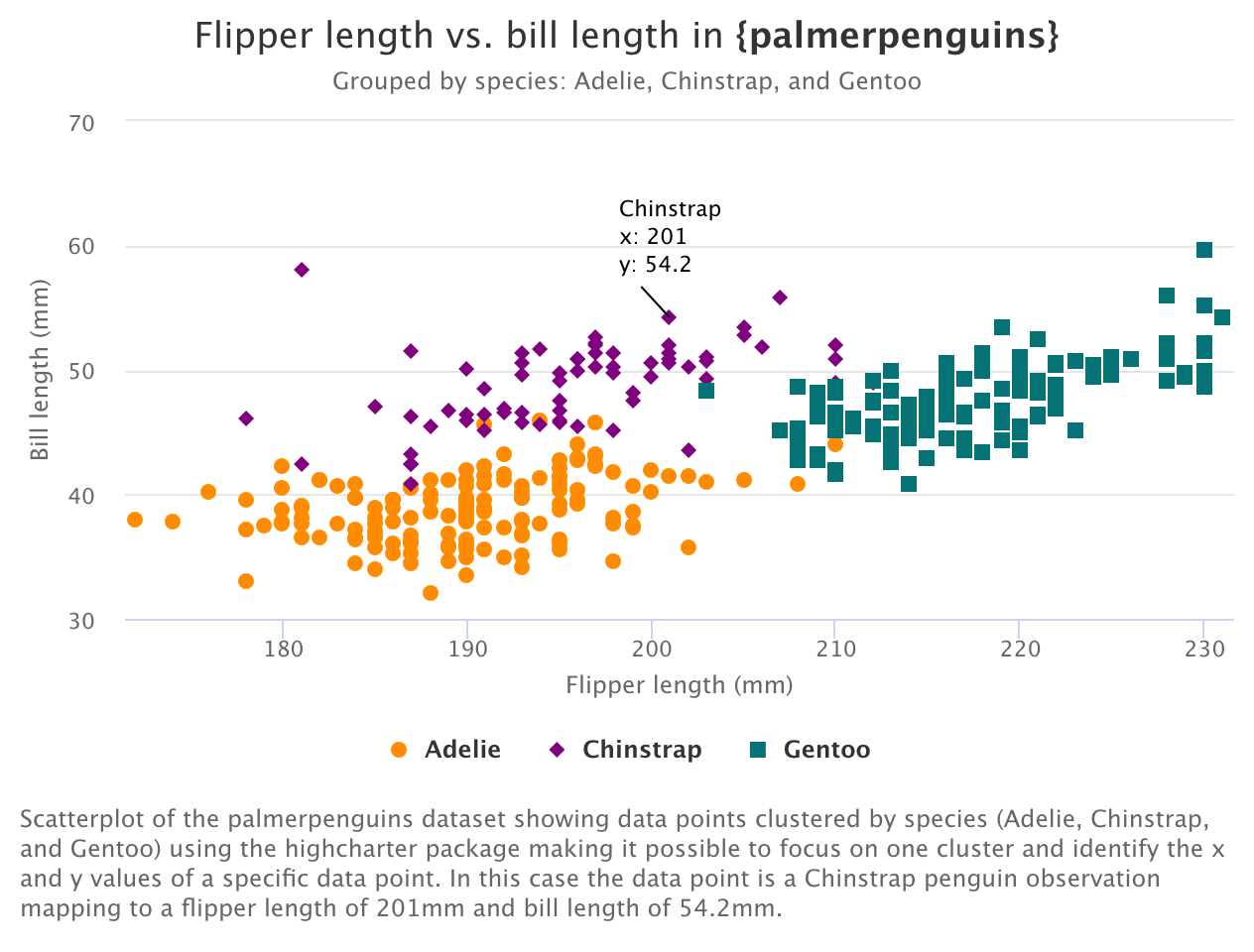
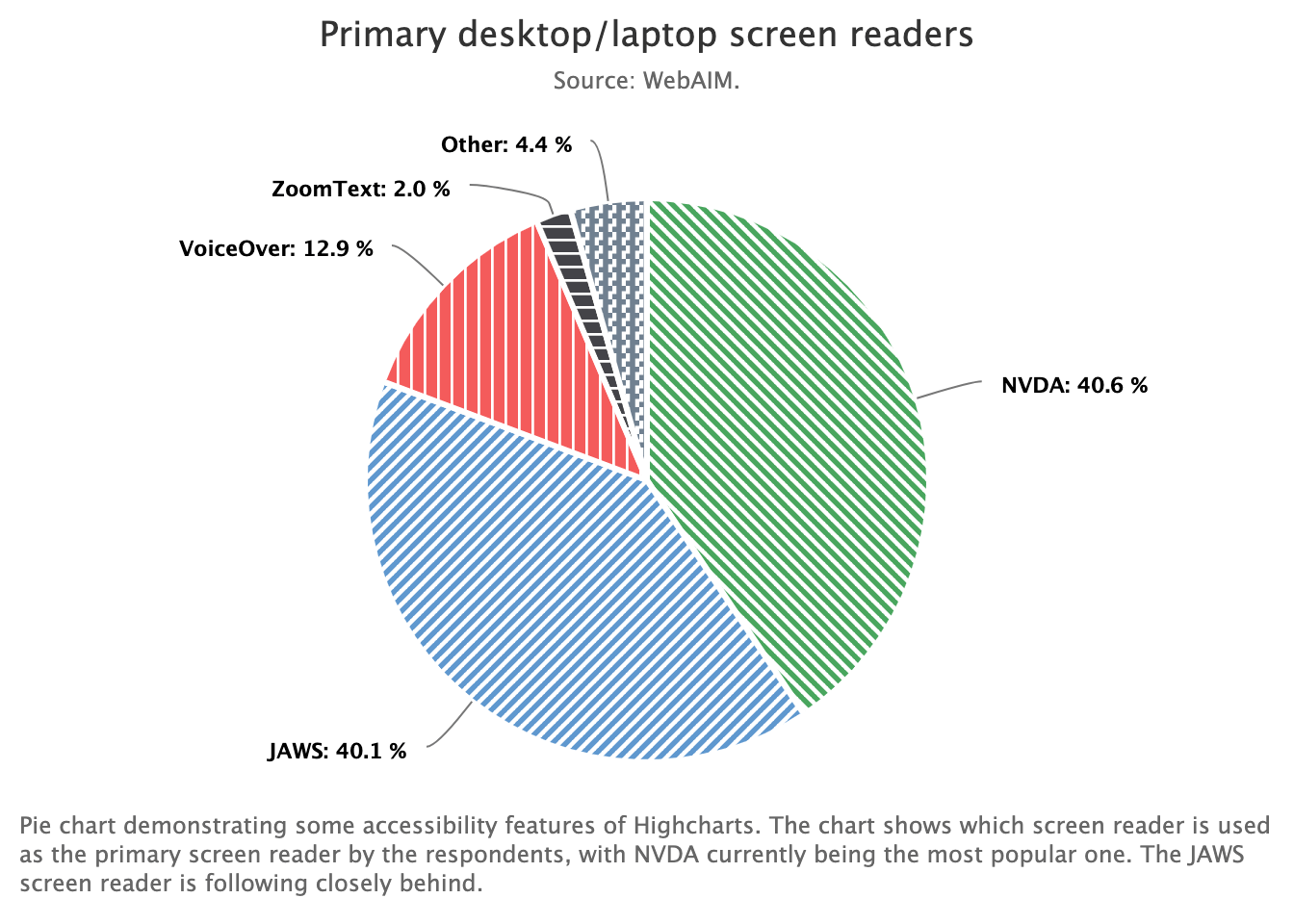
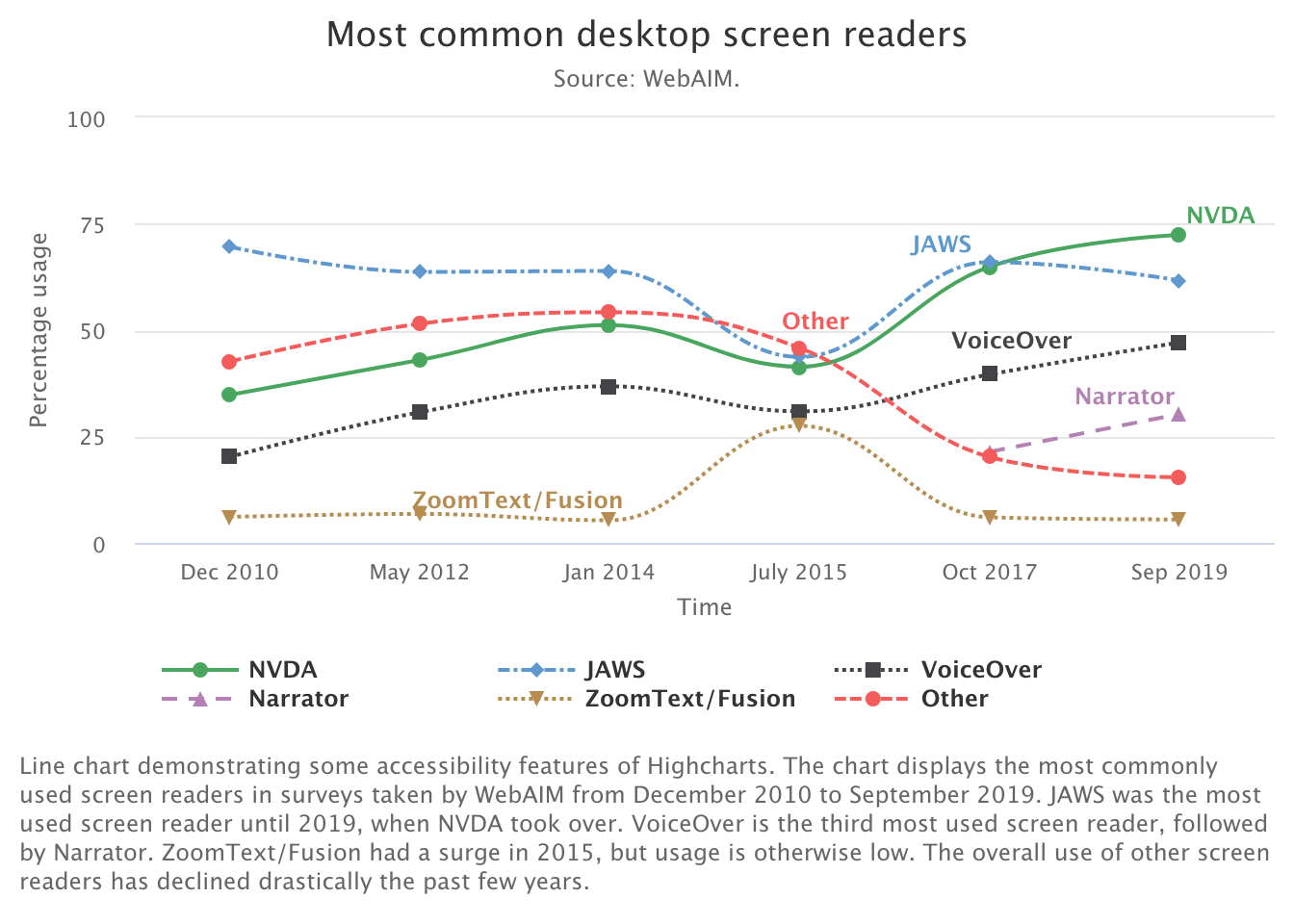
This final installment in our series on using the Highcharts accessibility module with {highcharter} is basically “extra credit.” (Read: I took the time to figure this out, so I’m sharing it. But, it’s probably not the most helpful post if you’re just trying to get the accessibility module working with {highcharter}.) We covered enabling the accessibility module, and getting basic keyboard navigation in part one.