Publicado in Henry Rzepa's Blog
Autor Henry Rzepa
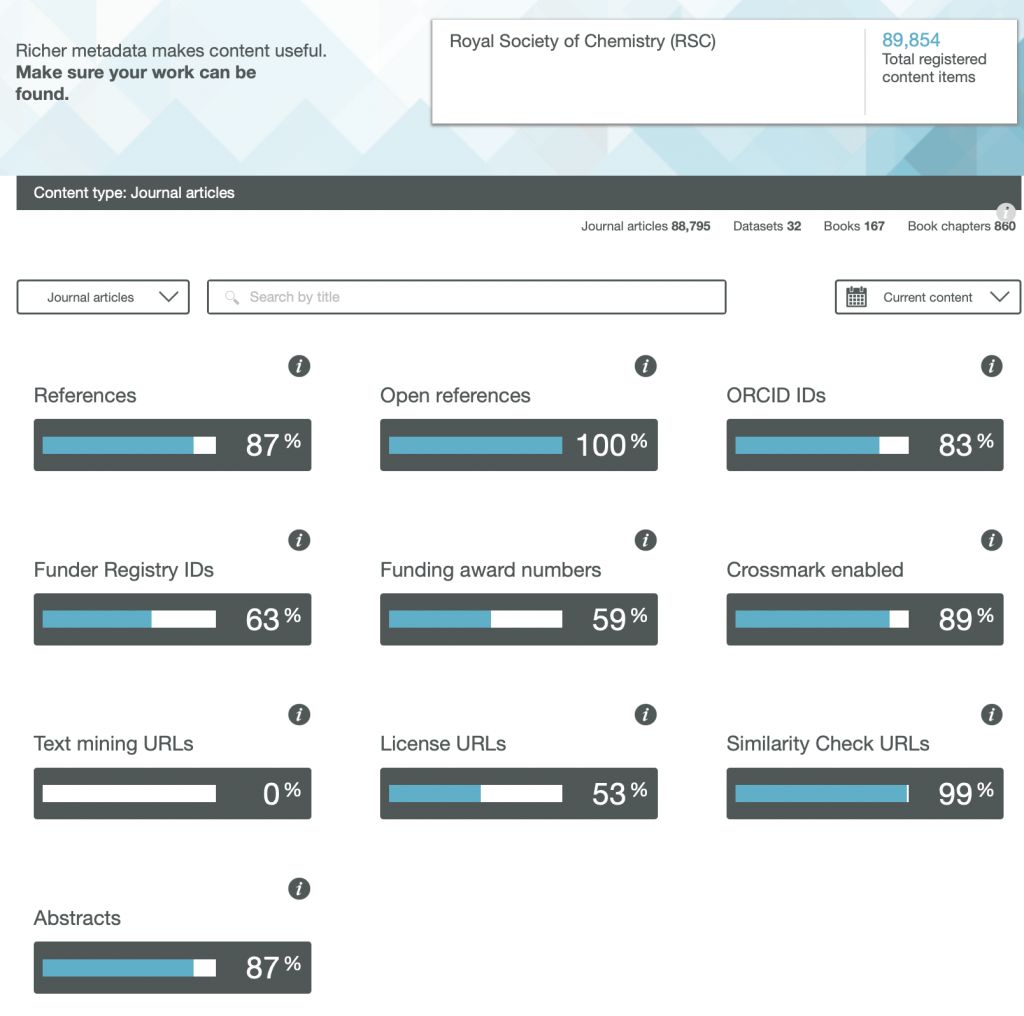
The title of this post comes from the site www.crossref.org/members/prep/ Here you can explore how your favourite publisher of scientific articles exposes metadata for their journal. Firstly, a reminder that when an article is published, the publisher collects information about the article (the “metadata”) and registers this information with CrossRef in exchange for a DOI.