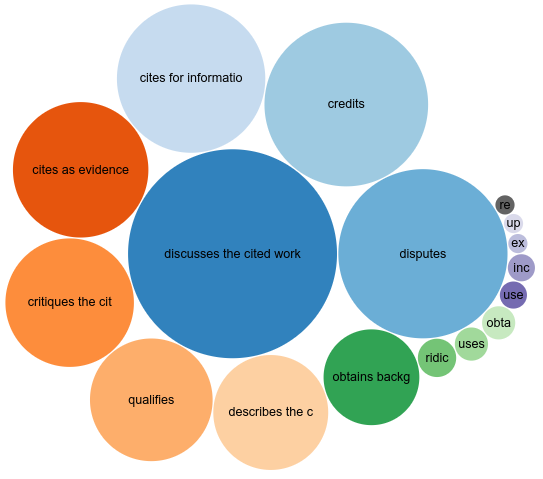
This summer I am trying to finish up some smaller projects that I did not have time for to finish, with mixed successes. I am combing this with a nice Dutch staycation, and I already cycled in Overijssel and in south-west Friesland and learning about their histories. But this post is about an update on my Citation Typing Ontology use cases. And I have to say, a mention by Silvio Peroni is pretty awesome, thanks! First, the bad news.
AbstractIn this article, we show the results of a quantitative and qualitative analysis of open citations on a popular and highly cited retracted paper: “Ileal-lymphoid-nodular hyperplasia, non-specific colitis and pervasive developmental disorder in children” by Wakefield et al., published in 1998. The main purpose of our study is to understand the behavior of the publications citing one retracted article and the characteristics of the citations the retracted article accumulated over time. Our analysis is based on a methodology which illustrates how we gathered the data, extracted the topics of the citing articles and visualized the results. The data and services used are all open and free to foster the reproducibility of the analysis. The outcomes concerned the analysis of the entities citing Wakefield et al.’s article and their related in-text citations. We observed a constant increasing number of citations in the last 20 years, accompanied with a constant increment in the percentage of those acknowledging its retraction. Citing articles have started either discussing or dealing with the retraction of Wakefield et al.’s article even before its full retraction happened in 2010. Articles in the social sciences domain citing the Wakefield et al.’s one were among those that have mostly discussed its retraction. In addition, when observing the in-text citations, we noticed that a large number of the citations received by Wakefield et al.’s article has focused on general discussions without recalling strictly medical details, especially after the full retraction. Medical studies did not hesitate in acknowledging the retraction of the Wakefield et al.’s article and often provided strong negative statements on it.
Autori AJ Wakefield, SH Murch, A Anthony, J Linnell, DM Casson, M Malik, M Berelowitz, AP Dhillon, MA Thomson, P Harvey, A Valentine, SE Davies, JA Walker-Smith
Abstract
WikiPathways (wikipathways.org) is an open-source biological pathway database. Collaboration and open science are pivotal to the success of WikiPathways. Here we highlight the continuing efforts supporting WikiPathways, content growth and collaboration among pathway researchers. As an evolving database, there is a growing need for WikiPathways to address and overcome technical challenges. In this direction, WikiPathways has undergone major restructuring, enabling a renewed approach for sharing and curating pathway knowledge, thus providing stability for the future of community pathway curation. The website has been redesigned to improve and enhance user experience. This next generation of WikiPathways continues to support existing features while improving maintainability of the database and facilitating community input by providing new functionality and leveraging automation.
This document contains the datasets and visualizations generated after the application of the methodology defined in our work: "A qualitative and quantitative citation analysis toward retracted articles: a case of study". The methodology defines a citation analysis of the Wakefield et al. [1] retracted article from a quantitative and qualitative point of view. The data contained in this repository are based on the first two steps of the methodology. The first step of the methodology (i.e. “Data gathering”) builds an annotated dataset of the citing entities, this step is largely discussed also in [2]. The second step (i.e. "Topic Modelling") runs a topic modeling analysis on the textual features contained in the dataset generated by the first step.
Note: the data are all contained inside the "method_data.zip" file. You need to unzip the file to get access to all the files and directories listed below.
Data gathering
The data generated by this step are stored in "data/":
"cits_features.csv": a dataset containing all the entities (rows in the CSV) which have cited the Wakefield et al. retracted article, and a set of features characterizing each citing entity (columns in the CSV). The features included are: DOI ("doi"), year of publication ("year"), the title ("title"), the venue identifier ("source_id"), the title of the venue ("source_title"), yes/no value in case the entity is retracted as well ("retracted"), the subject area ("area"), the subject category ("category"), the sections of the in-text citations ("intext_citation.section"), the value of the reference pointer ("intext_citation.pointer"), the in-text citation function ("intext_citation.intent"), the in-text citation perceived sentiment ("intext_citation.sentiment"), and a yes/no value to denote whether the in-text citation context mentions the retraction of the cited entity ("intext_citation.section.ret_mention").
Note: this dataset is licensed under a Creative Commons public domain dedication (CC0).
"cits_text.csv": this dataset stores the abstract ("abstract") and the in-text citations context ("intext_citation.context") for each citing entity identified using the DOI value ("doi").
Note: the data keep their original license (the one provided by their publisher). This dataset is provided in order to favor the reproducibility of the results obtained in our work.
Topic modeling
We run a topic modeling analysis on the textual features gathered (i.e. abstracts and citation contexts). The results are stored inside the "topic_modeling/" directory. The topic modeling has been done using MITAO, a tool for mashing up automatic text analysis tools, and creating a completely customizable visual workflow [3]. The topic modeling results for each textual feature are separated into two different folders, "abstracts/" for the abstracts, and "intext_cit/" for the in-text citation contexts. Both the directories contain the following directories/files:
"mitao_workflows/": the workflows of MITAO. These are JSON files that could be reloaded in MITAO to reproduce the results following the same workflows.
"corpus_and_dictionary/": it contains the dictionary and the vectorized corpus given as inputs for the LDA topic modeling.
"coherence/coherence.csv": the coherence score of several topic models trained on a number of topics from 1 - 40.
"datasets_and_views/": the datasets and visualizations generated using MITAO.
References
Wakefield, A., Murch, S., Anthony, A., Linnell, J., Casson, D., Malik, M., Berelowitz, M., Dhillon, A., Thomson, M., Harvey, P., Valentine, A., Davies, S., & Walker-Smith, J. (1998). RETRACTED: Ileal-lymphoid-nodular hyperplasia, non-specific colitis, and pervasive developmental disorder in children. The Lancet, 351(9103), 637–641. https://doi.org/10.1016/S0140-6736(97)11096-0
Heibi, I., & Peroni, S. (2020). A methodology for gathering and annotating the raw-data/characteristics of the documents citing a retracted article v1 (protocols.io.bdc4i2yw) [Data set]. In protocols.io. ZappyLab, Inc. https://doi.org/10.17504/protocols.io.bdc4i2yw
Ferri, P., Heibi, I., Pareschi, L., & Peroni, S. (2020). MITAO: A User Friendly and Modular Software for Topic Modelling [JD]. PuntOorg International Journal, 5(2), 135–149. https://doi.org/10.19245/25.05.pij.5.2.3