ChimicaInglese
Pubblicato in Henry Rzepa's Blog
Autore Henry Rzepa
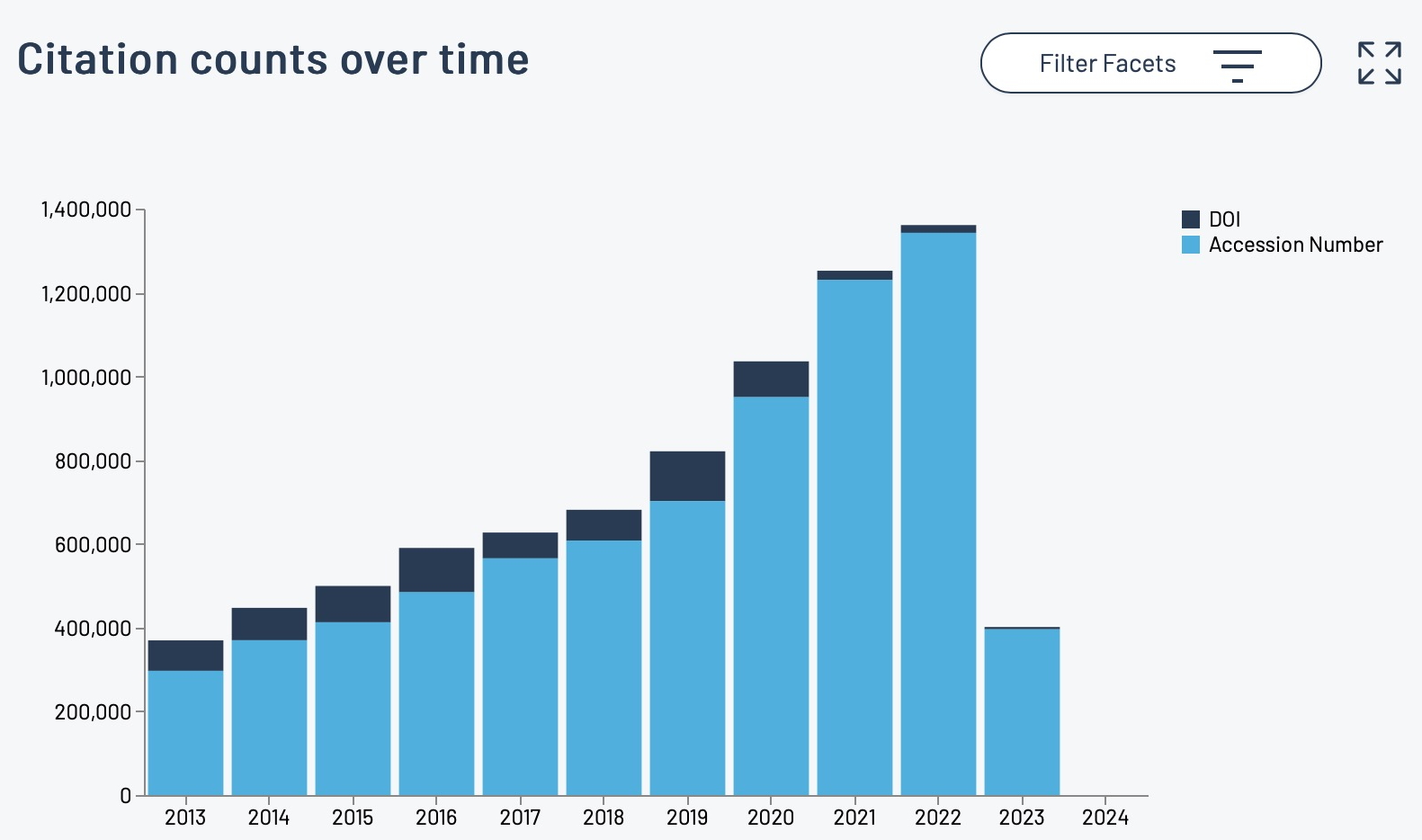
The recent release of the DataCite Data Citation corpus, which has the stated aim of providing “a trusted central aggregate of all data citations to further our understanding of data usage and advance meaningful data metrics” made me want to investigate what the current state of citing data in the area of chemistry might be. Chemistry is known to be a “data rich” science (as most of the physical sciences are) and here on this very blog I