Pubblicato in Recology
Autore Scott Chamberlain
I recently opened an issue in a repository for a package I’m working on to think about potential footguns and how to avoid them. That word “footguns” got me thinking;
I recently opened an issue in a repository for a package I’m working on to think about potential footguns and how to avoid them. That word “footguns” got me thinking;

On the Fediverse, @petrichor@digipres.club posited the question how to include identifiers for authors in Bib(La)TeX-based bibliographies: I have wanted to try including ORCIDs in bibliographies for a while now, and while CSL-JSON makes it nearly trivial to encode, neither CSL styles nor CSL processors are at the point where those can actually be inserted in the formatted bibliography.
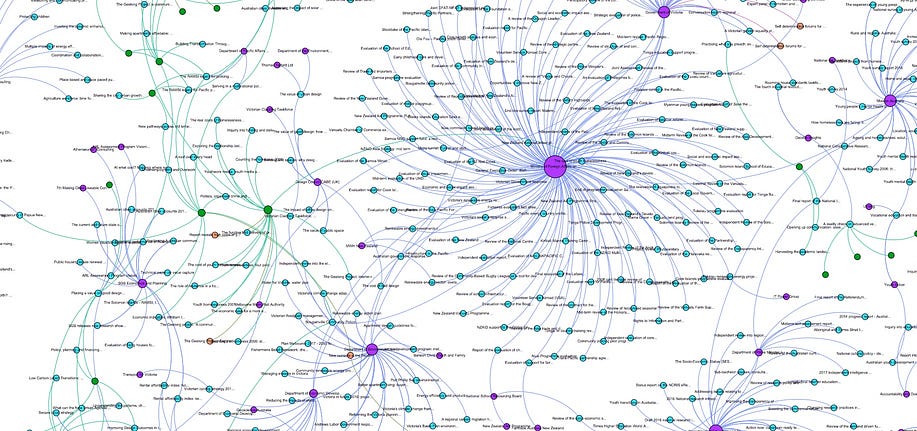
Author Amir Aryani (ORCID: 0000-0002-4259-9774) Introduction In this article we look at Research Graph as an information model , and an approach to connect and capture the connections between research outputs, researchers and research activities. We explore the metadata model, and we discuss how to capture this graph in a Neo4j Graph Database.
The package qualtRics maintained by Julia Silge together with Joseph O’Brien provides functions to access survey results directly into R using the Qualtrics API. Qualtrics is an online survey and data collection software platform. Help test or improve qualtRics! Are you a heavy user of the Qualtrics survey tooling in general, and of the qualtRics R package in particular? Then you can help build and test the package. How to help?
The package targets maintained by Will Landau, and its companion packages, are pipeline tools, that coordinate the pieces of computationally demanding analysis projects. Help sustain targets discussion forums!

re3data Call for Editorial Board The re3data.org registry has been in operation for over 10 years and provides a curated index of over 3,000 research data repositories around the world from all disciplines. New repositories are identified and reviewed by an international editorial board who bring different subject, language, and cultural backgrounds to catalog and represent a diverse and ever-growing data repository landscape.

Integrating Large Language Models (LLMs) such as GPT into organizations’ data workflows is a complex process with various challenges. These obstacles include but are not limited to technical, operational, ethical, and legal dimensions, each presenting hurdles that organisations must navigate to harness the full potential of LLMs effectively.

An Introduction to RA-CM3, MuRAG and RACE Author Xuzeng He (ORCID: 0009-0005-7317-7426) Generative Artificial Intelligence (GAI) has demonstrated impressive performances in tasks such as text generation and text-to-image generation.

Refining AI Vision: How Retrieval-Augmented Generation Transforms Image Captioning in Large Language Models Leveraging External Knowledge to Enhance the Descriptive Capabilities of AI Systems Author Vaibhav Khobragade (ORCID: 0009–0009–8807–5982) Introduction Large Language Models (LLMs) are artificial intelligence models that are trained on massive amounts of text data in order to generate human-like language and produce coherent

An Introduction to Retrieval Augmented Generation (RAG) and Knowledge Graph Author Qingqin Fang (ORCID: 0009–0003–5348–4264) Introduction Large Language Models (LLMs) have transformed the landscape of natural language processing, demonstrating exceptional proficiency in generating text that closely resembles human language.