Pubblicato in Henry Rzepa's Blog
Autore Henry Rzepa
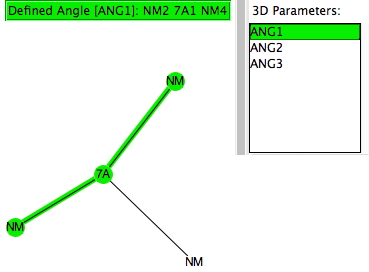
A while ago, I explored how the 3-coordinate halogen compound ClF 3 is conventionally analyzed using VSEPR (valence shell electron pair repulsion theory). Here I (belatedly) look at other such tri-coordinate halogen compounds using known structures gleaned from the crystal structure database (CSD). The search query specifies 7A as the central atom, defined with just three bonded (non-metallic) atoms.