Pubblicato in Stories by Research Graph on Medium
Autore Qingqin Fang
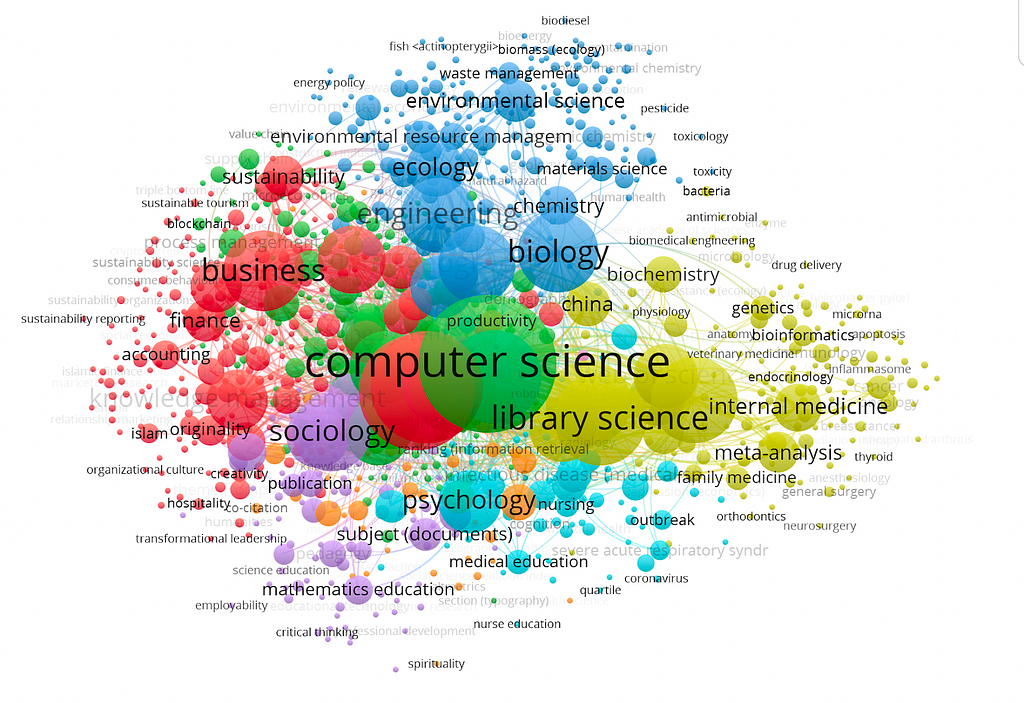
Exploring the OpenAlex Data Structure and Visualization Author: Qingqin Fang ( ORCID: 0009–0003–5348–4264) Introduction to OpenAlex In today’s world, the realm of research papers is brimming with countless hot topics, and the sheer volume of publications can be overwhelming.