Pubblicato in rOpenSci - open tools for open science
Autore David Winter
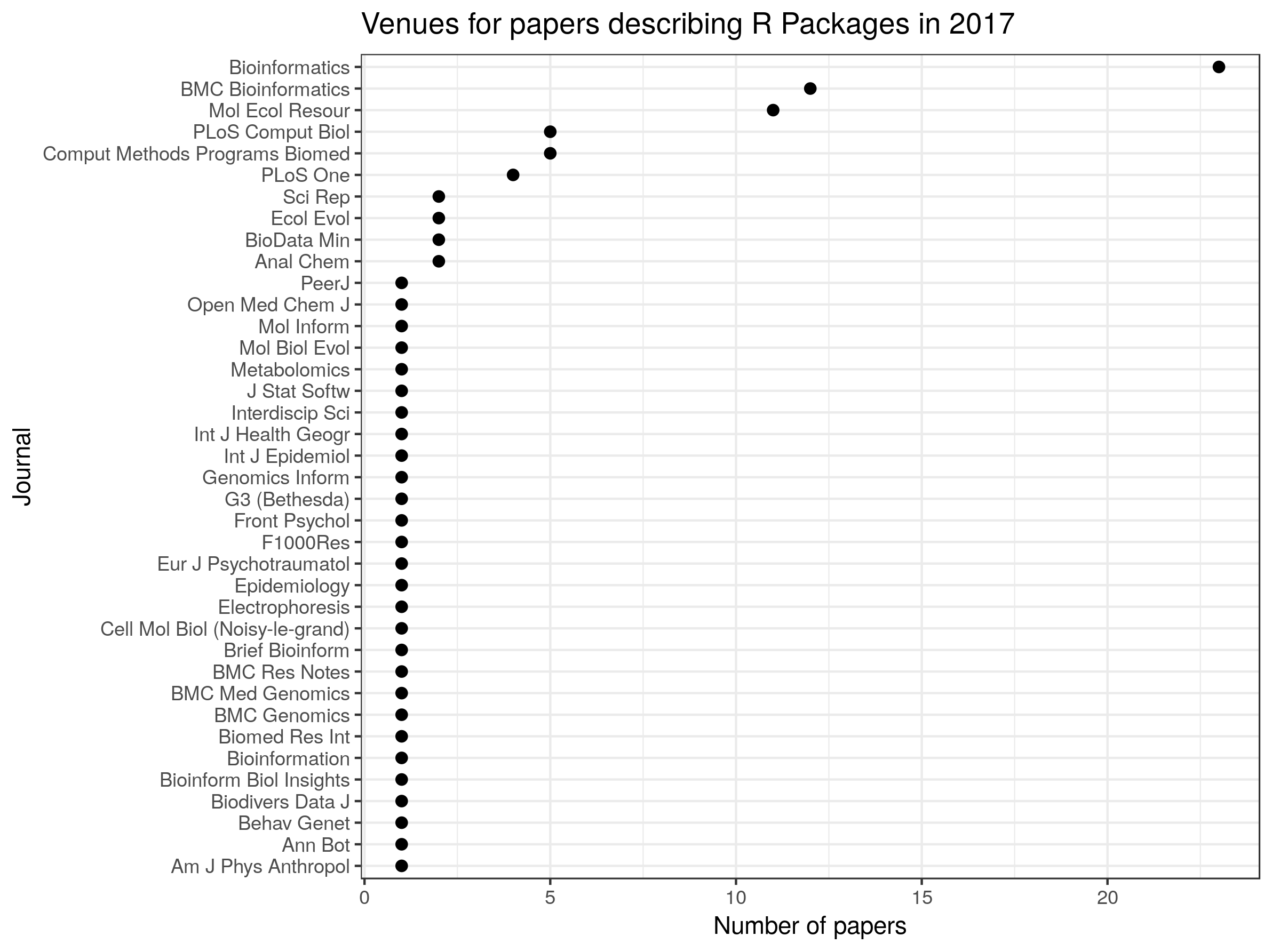
I am happy to say that the latest issue of The R Journal includes a paperdescribing rentrez,the rOpenSci package for retrieving data from the National Center for Biotechnology Information(NCBI). The NCBI is one of the most important sources of biological data. The centreprovides access to information on 28 million scholarly articles through PubMed and 250million DNA sequences through GenBank.