Pubblicato in chem-bla-ics
Autore Egon Willighagen
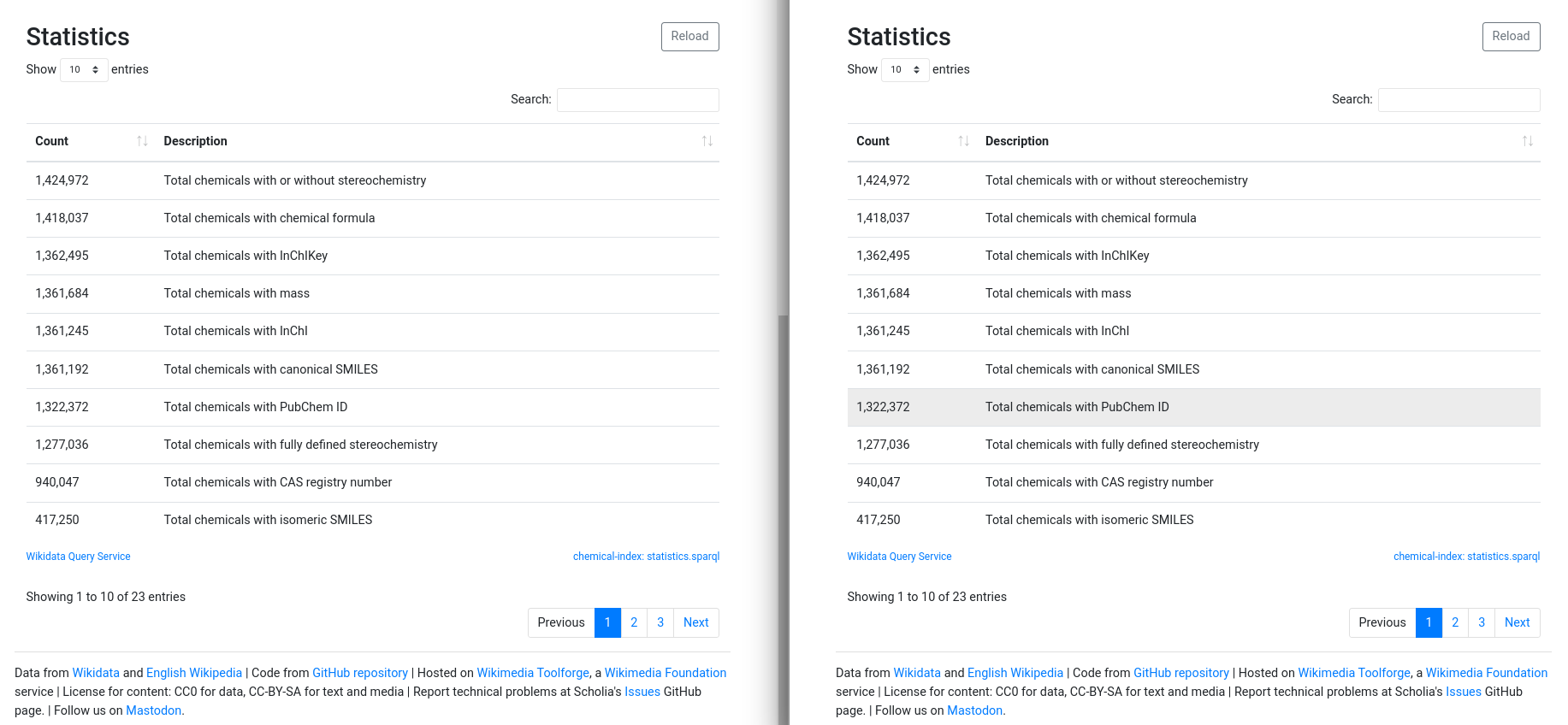
Scholia is a visual layer on top of Wikidata providing a rich user experience for browing scholarly research related knowledge. I am using the combinatie for various things, including exploring new research topics (a method, compound, or protein I do not know so much about yet), indexing notable research output (including citations), progress of Citation Typing Ontology uptake, etc.