Pubblicato in Front Matter
Autore Martin Fenner
Earlier this week I wrote a guest post for the Impact of Social Sciences blog.
Earlier this week I wrote a guest post for the Impact of Social Sciences blog.
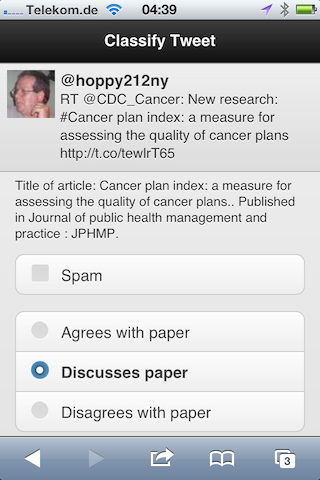
Two weeks ago Euan Adie from altmetric.com and myself launched the website CrowdoMeter, a crowdsourcing project that tries to classify tweets about scholarly articles using the Citation Typing Ontology (CiTO). Despite the holidays we have gotten off to a good start with currently 597 classifications by 56 different users, already covering 93% of the tweets we wanted to classify.
BibTeX is one of the most popular file formats for bibliographies, and is therefore commonly used to transfer bibliographies from one reference manager to another, or to other applications that handle bibliographic references. RIS and Endnote XML are probably the other two bibliographic file formats most commonly used. Most reference managers support all three formats, making it easy to move references around.

The shortDOI service was launched by the International DOI Foundation (IDF) in May 2010. The service creates short versions of the often long DOIs, e.g. 10/dvq instead of 10.1093/hmg/ddp202 – written as URL this would be http://doi.org/dvq instead of http://doi.org/10.1093/hmg/ddp202.

ScienceCard is a new service that I started last month with the simple idea to automatically track all journal articles of a given author, and to collect the article-level metrics (citations, bookmarks, etc.) for these papers. ScienceCard requires unique identifiers for articles and authors to work. Unique identifiers for authors is a difficult topic regularly discussed in this blog.

Yesterday I discovered (via a tweet by Owen Stephens) a very interesting document Personal names around the world that discusses the following question: The document was written by Richard Ishida, Internationalization Activity Lead at the W3C (World Wide Web Consortium). The document was published on July 26, and Richard was seeking comments until August 7 before finalizing the document.
Brendan Thomas has published an interesting paper that looks at author email addresses in the PubMed database of biomedical literature. Email addresses of first authors have been added to PubMed since 1996, and they can be retrieved via the standard web interface or automated software. This makes PubMed an excellent place to find the email address of an academic author, but also shows that PubMed is very vulnerable to email address harvesting.
At the beginning of the month Google, Bing and Yahoo announced schema.org, a new initiative for structured markup on the web. Richard MacManus responded with a critical piece at ReadWriteWeb (Is Schema.org really a Google Land Grab?), mainly criticizing that the initiative didn’t use RDFa and didn’t seem to have consulted with the web standards body W3C.

Ten days ago I mentioned a paper by Zhiyong Lu that gives an overview over the available web tools to search the biomedical literature. Most of these tools enhance the PubMed service, and Zhiyong Lu in fact works for the NCBI, the developer of PubMed. In this post I want to take a more detailed look at the available tools. A good starting point is the companion webpage to the paper, listing 28 services.
Zhiyong Lu recently published an excellent overview of the web tools that are currently available to search the biomedical literature. The article has also a companion web page that allows user to filter for the features they are interested in, and to report new tools. The author describes 28 tools developed specifically for the biomedical domain.