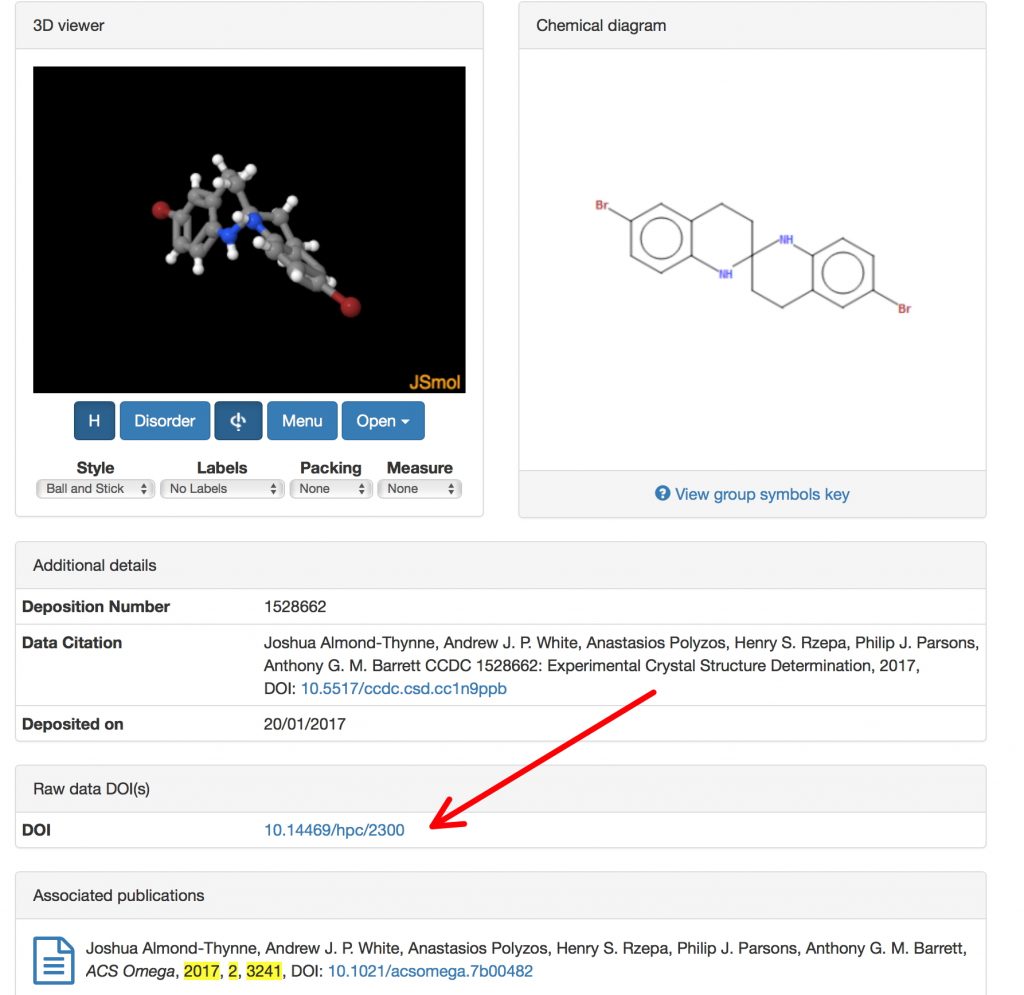
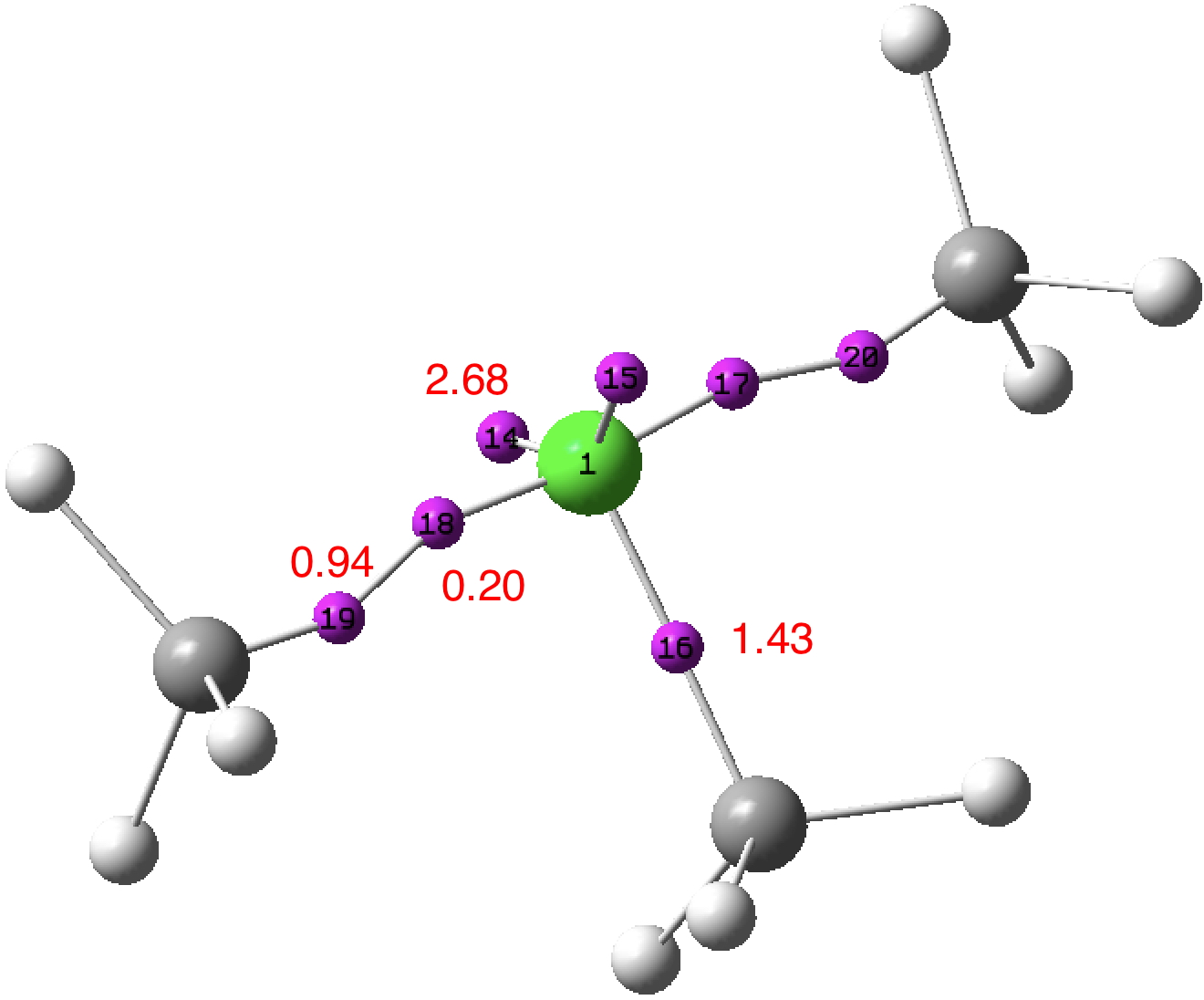
Pubblicato in Henry Rzepa's Blog
Autore Henry Rzepa

Linear free energy relationships (LFER) are associated with the dawn of physical organic chemistry in the late 1930s and its objectives in understanding chemical reactivity as measured by reaction rates and equilibria.