Transformers Models in NLP


Attention mechanism not getting enough attention
Author
- Dhruv Gupta (ORCID: 0009–0004–7109–5403)
Introduction
As discussed in this article, RNNs were incapable of learning long-term dependencies. To solve this issue both LSTMs and GRUs were introduced. However, even though LSTMs and GRUs did a fairly decent job for textual data they did not perform well. Transformer-based models which first came out in 2017 took the Natural Language Processing (NLP) world by storm. They were initially introduced to solve the problem of sequence-to-sequence translation. However, they have now become the backbone of almost all the generative AI models. Models like GPT-3 and BERT, use large transformer-based models for training on huge amounts of data. In this article, we will discuss the architecture of transformer-based models and how the attention mechanism works.
Transformers
Transformer-based models introduced two new concepts which changed the field of NLP forever. They were attention-based models and encoder-decoder models. The concept of attention-based models allowed the language models to focus on only important parts of the text. This gave the model the ability to comprehend the long-term dependencies. In addition to this, the attention mechanism along with the encoder-decoder architecture of the transformer, empowered the model to comprehend the subtle nuances in the text and get the textual data, like how we humans do it.
What is the Attention mechanism?
The attention mechanism allows a machine learning model to emphasise certain aspects of the input data and this forms the heart of a transformer model. However, the transformer model uses a set of self-attention blocks. Self-attention blocks allow the model to focus on different positions of a single sequence thereby computing a representation of the sequence. So the important question is how does this attention mechanism work?
Keys, Values, and Queries?
Keys, values, and queries are the heart of the self-attention mechanism. They are used to calculate the self-attention weights using the input X. The input X is multiplied by weight matrices that are learnt during training.
- Query Vector (Q) = X Wq. It can be thought of as the current word.
- Key Vector (K) = X Wk. This acts as the index value of the value vector.
- Value Vector (V) = X Wv. Can be considered as the information stored in the input word.
What self-attention does is that for every query (Q) the most similar key K, is calculated using the dot product between Q and K. The dot product is then multiplied with a v vector to get the information stored in the input word.

Architecture
The transformer uses an encoder-decoder architecture. The idea behind such an architecture is that the encoder processes the input data and transforms it into a different representation, which is then subsequently decoded by the decoder to produce the desired output. Transformers which were originally designed for translation use this architecture a bit differently. The encoder is given the input sentence and the decoder is given the same sentence in the target language. However, the decoder only gets the words that have been translated. For example: if there are 5 words in a sentence and three have been translated. The decoder will get the already translated words and the original input sentence and will try to predict the fourth word.
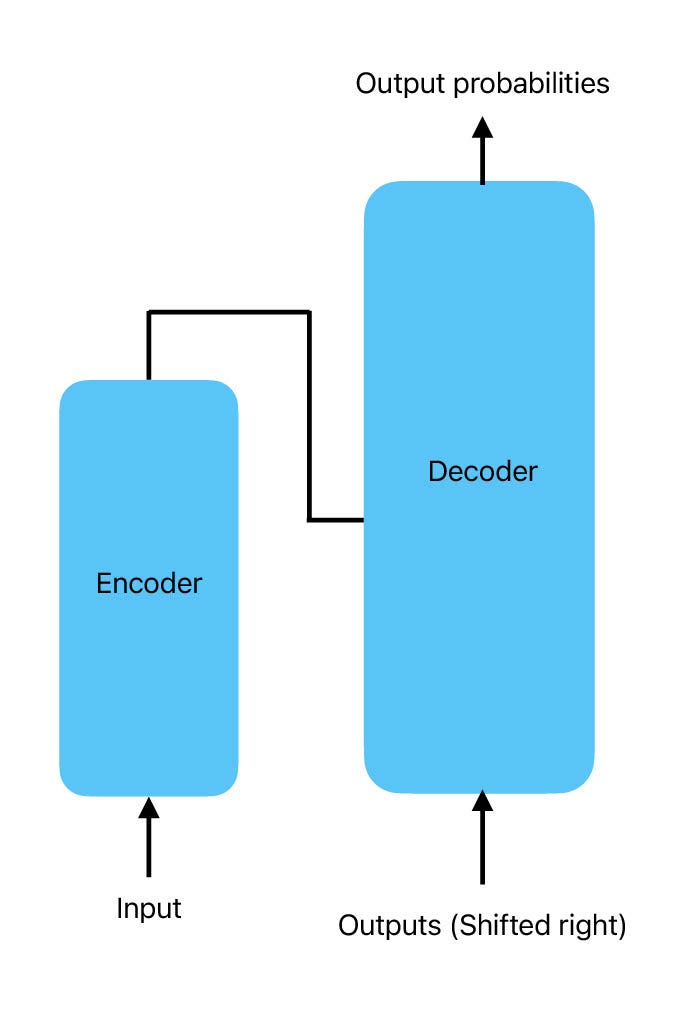
Diving into the Architecture
As discussed in the above section the transformer model consists of an encoder-decoder model.

Encoder
The input data is first converted into word embeddings which are then concatenated with the positional embeddings. The positional embeddings play an important role because the word embeddings themselves lack the positional information which plays a crucial role in textual data. The encoder model has two sub-layers: multi-head self-attention and the feed-forward neural network. The multi-head self-attention model consists of a self-attention mechanism which is applied parallelly. This output is then passed through to the feed-forward neural network which then learns from the output of the attention model.
Decoder
The decoder also consists of a similar sub-layer as the encoder. There is a masked multi-head attention block which works on the output vectors of the previous iteration. The multi-head attention block works on the output of the encoder and masked multi-head attention in the decoder. The output of the attention block is then passed through to a fully connected feed-forward neural network which then produces the output probability for the next words.
The output of the decoder model is fed into the decoder again just like a typical RNN model. The masked multi-head attention block is used to mask the future words so that the decoder only generates the output using the previously seen outputs and previously seen input from the encoder model.
Are they still worthy?
Transformer models which first came out in 2017 for language translation have changed the face of NLP. While NLP tasks are where transformers are at their peak, they have a lot of other applications outside of text processing. They can be used for tasks such as speech recognition, image captioning, text classification, among others.
Apart from solving NLP-related tasks, transformer models have also formed the backbone of the new-age generative AI models. Most of the generative AI models such as GPT, GPT-3, and BERT have stacks of transformer models in them because of their excellent feature extraction capability. Additionally, the newer version of generative AI models such as RAG also has transformer-based encoder-decoder models working in the backend.
Additionally, big companies such as Google, Facebook, Vault, and Grammarly which are heavily focused on NLP-based applications still use transformer-based models in the backend. Their ability to accurately recognise patterns and context in data makes them an invaluable tool in the field of NLP.
Therefore, in conclusion, with continued advancements in the field of LLM, transformers have a big role to play. Hence, with a vast array of applications and even more to follow, transformers are still worthy of solving almost all complex NLP-based tasks.

References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I. (2017). Attention Is All You Need. [online] arXiv.org. doi:https://doi.org/10.48550/arXiv.1706.03762.
- Kulshrestha, R. (2020). Transformers. Medium. Available at: https://towardsdatascience.com/transformers-89034557de14.
- huggingface.co How do Transformers work? — Hugging Face NLP Course. [online] Available at: https://huggingface.co/learn/nlp-course/en/chapter1/4
- Kulshrestha, R. (2020b). Understanding Attention In Deep Learning. Medium. Available at: https://towardsdatascience.com/attaining-attention-in-deep-learning-a712f93bdb1e.
Additional details
Description
Attention mechanism not getting enough attention Author Dhruv Gupta ( ORCID : 0009–0004–7109–5403) Introduction As discussed in this article, RNNs were incapable of learning long-term dependencies. To solve this issue both LSTMs and GRUs were introduced. However, even though LSTMs and GRUs did a fairly decent job for textual data they did not perform well.
Identifiers
- UUID
- ea19ac73-b8fd-418e-bdce-603fb09fecec
- GUID
- https://medium.com/p/322fb0e912cf
- URL
- https://medium.com/@researchgraph/transformers-models-in-nlp-322fb0e912cf
Dates
- Issued
-
2024-05-07T01:58:49
- Updated
-
2024-05-07T01:58:49