Google Scholar vs other AI search tools (Undermind, Elicit, SciSpace) - how and when to use each


Google Scholar turned 20 last month and Nature wrote a piece with the title "Can Google Scholar survive the AI revolution?" and quoted as saying
"Up until recently, Google Scholar was my default search," says Aaron Tay, an academic librarian at Singapore Management University. It's still top of his list, but "recently, I started using other AI tools."
This led me to think, how and when do I use Google Scholar vs other "AI search tools"?
Suffice to say, Google Scholar, which is by far the biggest single source of academic papers (and this includes full-text indexed), and as the single most dominant academic search tool used by researchers in the world across almost all disciplines, it is under no danger of being obselete.
In my view, Google Scholar is the swiss army knife of academic search, if I did not know in advance what my use case would be and I could pick only one academic search tool, it would be no brainer to pick Google Scholar.
But of course we are not limited to picking one tool, so this is my personal view of how Google Scholar compares to some AI tools.
Some ground rules
I am going to consider Google Scholar and these new AI search tools only in the context of the quality of their search results found by inputting queries.
I am not taking into account other specific features, e.g AI specific features like available of Retrieval Augmented Generation (RAG) answers, functionality to extract data for synthesis matrix etc.
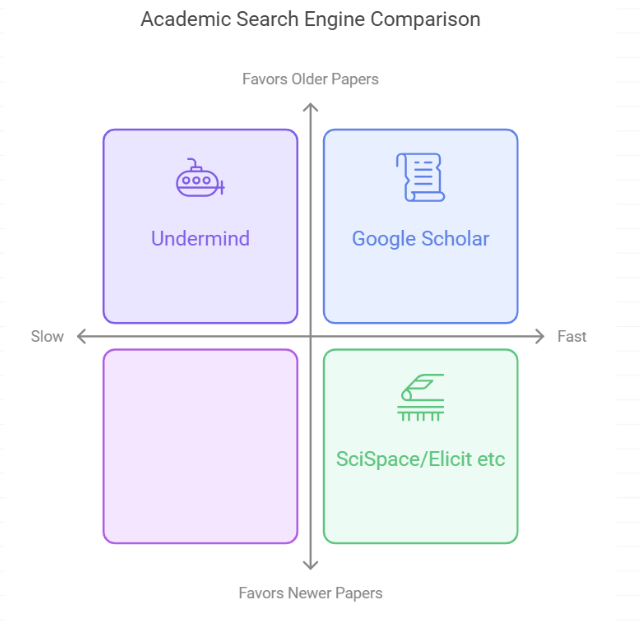
I am going to focus on three main type of academic search tools as I see it.
1. Google Scholar - Lexical, keyword based academic search
2. Undermind.ai - Agent based search with iterative searching
3. Elicit.com/SciSpace etc - Hybrid search using blend of Lexical search AND Semantic search (or in the case of Elicit.com uses SPLADE, a learned sparse embedding method which is a blend of the two).
There are many more in this category but I will stick with the ones I know the best.
I am comparing these three groups because they are based on indexes of roughly the same size and composition - cross-disciplinary inclusive scholarly indexes of 200M+ but work differently enough in the way they search that leads to different use scenarios.
Of course, there are other classes of academic search tools that are smaller worth considering based on different factors to consider when choosing where to search including
if you want to restrict searching to only "top tier journals" then pick Scopus/Web of Science
if you want to pick up papers as early as possible then pick preprint servers like SSRN
If you want to consider specialised database with high relative % coverage of papers in your discipline (use SearchSmart to determine this - see also this paper with highly detailed guidelines on how to do this).
if you want to use powerful search features such as support of advanced boolean functionality (e.g. Proximity, nested boolean), many field searching capabilties, controlled vocab etc then pick Lens.org or OpenAlex for cross-disciplinary and subject databases like Medline, Econlit, Psycinfo for subject specific sources.
And least, I forget, you can complement search also with citation chasing/searching type tools....
Google Scholar - the overall default choice
When to use - Scenario 1:
Google Scholar is my default and favourite academic search engine, particularly when I am exploring a new academic area, I know little about. The algo (see later) tends to favour papers that match the title and is highly cited.
This means that if you search with general keywords with a lot of matches, you are likely to see seminal papers on the topic or review type papers that appear on top of the result page.
There is also a filter feature called review articles in Google Scholar that can help identify such review articles which might be useful to start a project.
When to use - Scenario 2:
According to Searchsmart estimates in term of coverage Google Scholar bests the next biggest academic search tools by large margins, including OpenAlex, Lens.org, Semantic Scholar etc. But even that misses the point. Google Scholar coverage is not just in terms of title & abstract but also coverage of full-text of most major publishers, which is totally unmatched. This is a unique advantage that can be exploited for specialized use cases where matching full-text is critical.
For example, recently I was trying to see how frequently certain tools like ResearchRabbit, Elicit.com, Connected Papers are used in literature review. This would be impossible to do with typical search engines that cover only title/abstracts since such mentions would typically be in the methods section. Similarly if you have very unique specific terminology or jargon, that can be found in full text, Google Scholar would probably be the only source to use.
Algo favours: As noted above Google Scholar weights papers with high citations heavily after title matches.
Main weakness : Google Scholar is one of the most powerful generalist tools out there and has relatively few weaknesses. If there is any weakness, it is that it's algo is still lexical/keyword based and while it offers some filters and field searches in the "advanced search" compared to most conventional databases it has somewhat weaker search related features. For example,
a) limitation in the length of the search string you could use (256 characters)
b) No support of parenthesis for nested boolean
c) Limited field searching (e.g you can do title search only but not abstract)
d) No left/right truncation
e) Lack of controlled vocab etc
Sidenote: If you want a search that has an index that covers almost as broad as Google Scholar but yet with more powerful search functionality, the two best ones are Lens.org and OpenAlex. However they don't have as much full-text as Google Scholar of course.
This lack of features to support high precision searching is further compounded by the fact that Google Scholar has a lot of full-text which can leads to a lot of matches compared to just matching metadata (even with exact same coverage in terms of works), which is exactly the scenario where you would want to use such features!
For example, comparing the exact same input in Google Scholar, vs any other academic database, you will notice Google Scholar returns many more results. Besides Google Scholar having the largest index, a lot of these results are due to matches in the full-text which most systems do not have.
For example in the earlier example where I wanted to see if specific discovery and search tools were being used in the literature review, I wanted to search for a tool which had unfortunately a common name - Elicit. This made it useless because as Google Scholar covered the full-text, searching for "Elicit" would give too many false hits. If Google Scholar allowed field searching or limit searching to say the methods section only, this would be a solution, but it does not. A workaround in this particularly case would be search for the domain Elicit.com or Elicit.org
This and the lack of features like bulk export, maximum 1000 results and others explains why Google Scholar isn't a good tool for systematic reviews.
Undermind.ai - the slow but powerful specific searcher
When to use - Scenario 1: Undermind is great to use when you are looking for specific types of papers and want a pretty comprehensive search
I've blogged about Undermind.ai before and here is a more recent review.
Two things distinguish it from Google Scholar and even other "AI search tools".
Firstly, instead of just using relevancy ranking methods like TF-IDF/BM25 or even cosine smilarity of embeddings for AI search like SciSpace etc, Undermind.ai also uses a LLM like GPT4 to determine relevance (it is a type of reranker).
My understanding is Undermind initially uses a blend of keyword and semantic search (see later) to rank top candidates that might be relevant (using title/abstract matches), and some of them are then sent to a LLM like GPT4 which is fed with the query, title, abstract and other available metadata from the Semantic Scholar corpus and asked to make a decision on relevancy. Latest versions of Undermind, might even use the full-text if is open access and available in Semantic Scholar Corpus.
In short, instead of giving a relevancy score, typically based on how many keywords in the search match our documents (term frequency) and how rare what is being matched in the whole document corpus (inverse document frequency), the fact that Undermind.ai uses GPT4 to assess relevancy means that Undermind.ai is capable for looking for very specific type of papers when expressed in natural language.
This is why Undermind.ai urges you to tell it "exactly what you want, like a colleague" and it will understand. Various studies including one from Undermind themselves and other papers seem to suggest GPT4 has a roughly 90% agreement with humans on various tasks including judging what is relevant and what isn't versus human judgement.
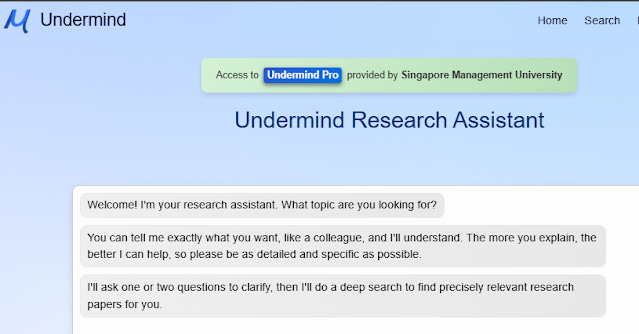
In fact, Undermind will "badger" you (at least feels that way to me) to type more in detail no matter how detailed you write your initial query by using GPT4 to prompt you to say more... But I guess this is a safeguard as most people are used to typing in short general keywords.
The other important difference is at the time of writing in Dec 2024, Undermind.ai is the only off-the-shelf academic search that has agent like search and does iterative search where the systems claims to adapt search, use citation searching etc via multiple rounds just like human researchers do.

Our testing show that between iterative searching AND using GPT4 directly to evaluate results, Undermind is very good at producing high quality result sets.
One way to measure quality of results is using systematic review included papers as ground truth. At their best these are very through and comprehensive searches that serve as a gold standard. For example, using "Efficacy of digital mental health interventions for PTSD symptoms: A systematic review of meta-analyses" as a gold standard, Undermind found 8 out of 11 in the top 10 results, a recall@10 of 72.7%. It found one more at position 44, with a recall@50 of 81.8%! Of course, Undermind's effectiveness varies hugely based on domain, type of query etc, but I dare say, for most topics as long as it is a query for specific papers (as opposed to general attempts to explore), it's recall@10 and recall@50 should beat most typical academic search engines whether they use keyword e.g. Google Scholar or semantic search like Elicit.com as long as they don't employ multiple iterative searches.
But this better quality result is of course at the cost of speed, as you need to wait 3 minutes at least for the results to come back.
When to use - Scenario 2: Similar to the first scenario, you can try to look for very specific papers that you don't think exist and try to disprove yourself using Undermind. This doesn't work as well as Scenario 1 but is worth a try. Even if Undermind.ai does not find the paper you are testing for, it may still exist and you have to do other methods like citation searching etc but it does reduce the probabilty and I use this often as a first step.
Algo favours: Unlike AI tools with "semantic search" (see later) but similar to Google Scholar, Undermind.ai does have a slight bias towards finding seminal and highly cited papers, this is because it's iterative search also uses citation searching as well as keyword which increases the chances of finding highly cited papers.
Main weakness : Undermind's use of agent-like search increases the quality of results, but this comes at the cost of time as each query lasts at least 3 minutes. This means you shouldn't be using this for quick quick exploratory searches.
Even if speed wasn't an issue, it shines particularly when you are looking for very specific papers.
In other words do not search for general topic like
impact of chatgpt or Large language models on research
This is too general a topic, and while Undermind might do okay, it is probably not worth waiting 3 mins for this when you can just get equally good if better results immediately with Google Scholar (cos there are so many possible matches).
A much better use of Undermind would be to to look specifically for papers on one particular use that might affect research. For example, looking at some overview papers found by Google Scholar you might realise people are trying to use LLMs in systematic reviews. More specifically, one way of using them is as a title-abstract or full text screener. Undermind could then be used to help find as many papers as possible like that. For example.
Find papers that use ChatGPT or LLMs as a title-abstract screener for systematic reviews.
You can add even more details like saying you want papers that measure performance using metrics like Precision, Recall etc.
One weakness of Undermind to take into account is that Undermind, generally takes into account only title and abstract (and to some extent full text of open access papers), so if the query requires access to full-text to match the query it can come up short.
Also as much as frontier LLM models like GPT4 correlate with human judgements of relevancy, it is not 100% reliable and Undermind's interpretations of papers can be off under "Paper Relevance Summary" (it goes without saying the "Discuss the results with an expert" section based on retrieval augmented generation technique has similar issues)
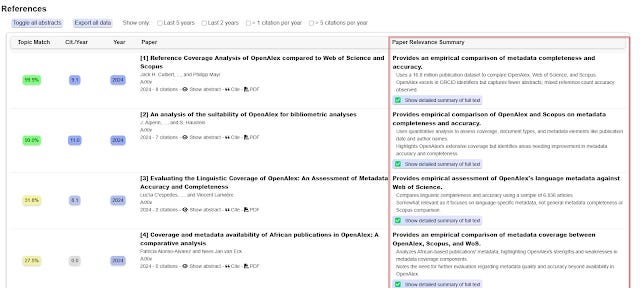
In short, I find Undermind.ai works much better for looking for very specific papers.
You can try queries that are in between searching very broad topics and searching very specific papers but I've seen comments that the "scope of text and references found by Undermind is a bit narrow, and it doesn't explore as much the wider range of topics/references connected to the research questions asked".
Essentially the way I see it, it isn't very active in connecting the dots and sticks closely to common sense connections making it less comprehensive for broader topics.
Elicit.com, SciSpace etc - the new semantic searcher
When to use - Scenario 1: When you are not quite sure what is the right keyword and/or want to search in natural language. While a bit slower than lexical search engines like Google Scholar, it is still fast enough for you to use for general exploratory queries.
The main difference between the new "AI search" tools like Elicit.com and SciSpace is that they go beyond traditional keyword/lexical search (typically boolean + ranked by BM25) to do more semantic search.
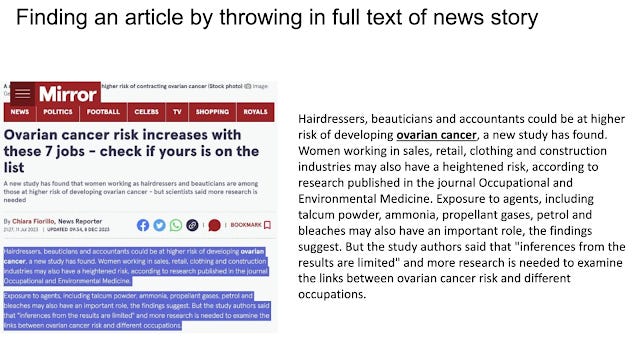
Semantic search these days involve the additional use of dense embeddings (or in the case of Elicit.com, they use SPLADE which is a hybrid technique, basically sparse embeddings trained to act like dense embedding) which allows the search algo to better match documents to queries based on overall "meaning", hopefully letting you find relevant papers even without the exact keywords.
This can work beautifully, such as throwing in a chunk of text from a newspaper article talking about the results of a journal article and semantic search surfacing the very journal article due to the system finding the document with the closest semantic similarity to the text chunk entered!
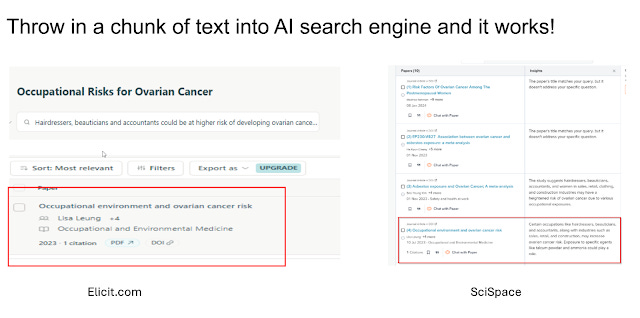
Semantic search based on embedding similarity match is a bit slower than traditional keyword search (you can notice a bit of delay compared to Google Scholar) but still fast enough you can use it for general exploratory searches exactly like Google Scholar.
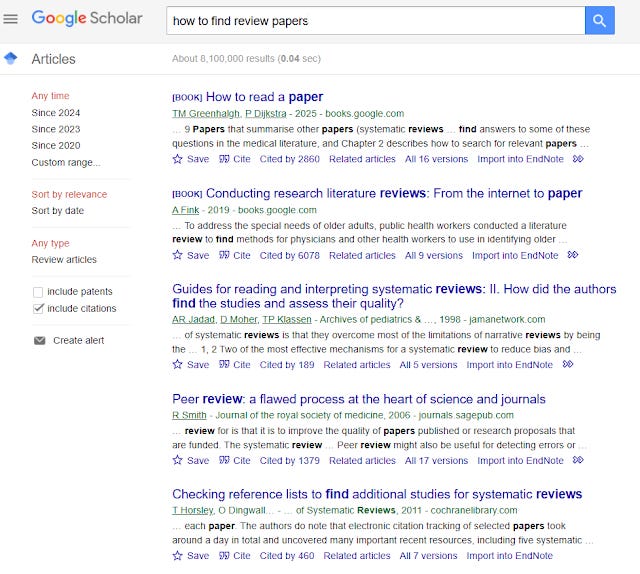
Unlike Google Scholar and other lexical search based search engines, you should query Elicit or SciSpace with natural language style (e.g. Techniques to find review papers) rather than keyword style (e.g. Techniques review papers).
For sure trying natural language queries in Google Scholar, tends to lead to worse results. Below shows Google Scholar totally messing up the query
how to find review papers
Algo favours: Both Elicit and SciSpace tends to use only semantic similarity for ranking papers and do not weight citations. As a result compared to Google Scholar, they tend to favour new papers vs older ones.
With both Elicit and SciSpace, you have the options to do a post filter of the results by the tier a journal is in
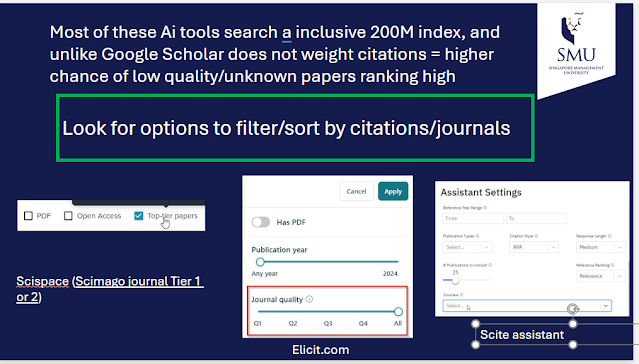
Weakness : As mentioned already, Elicit and SciSpace focus on semantic similarity for ranking, this coupled with the fact that they use inclusive sources of over 200M records without weighting for citations, they tend to not favour older, well cited papers compared to Google Scholar whose algo weights citations heavily. This coupled with the large inclusive index this means they can surface relatively unknown and often low quality papers to the top ranks just due to semantic similarity.
To handle this, both Elicit and SciSpace have post filters that allow you to filter by Journal quality (Scimago Journal Rank - SciSpace covers Q1 & Q2)
To be fair, not all tools that use semantic search ignore citations, some like Scite.ai Assistant and Consensus.ai claim to use citation counts as a ranking signal.
Another slight disadvantage of these tools is their results are often non-deterministic. That is, if you rerun the search you can get different results.
Why are "AI search"/Semantic search non-deterministic? There are many technical reasons. LLMs like ChatGPT are famously non-deterministic even if you turn down hyper parameters like temperature, top P or top K. LLMs can be used in search for multiple reasons from formulating a boolean search to doing search extensions leading to non-deterministic results. Other reasons could be due to the search algo using approximate rather than exact nearest neighbour search to match semantic closest embeddings leading to different results for different seeds. Then there is the whole issue of parallelization...
Conclusion
These are some of my thoughts on using different combination of AI search tools to complement use of Google Scholar taking into account just the relevancy of the results. In reality, I use many AI search tools not so much for the search but more for accuracy of features like generating direct answers via RAG or extracting data into synthesis matrix (e.g. Elicit, SciSpace).
Additional details
Description
Google Scholar turned 20 last month and Nature wrote a piece with the title "Can Google Scholar survive the AI revolution?" and quoted as saying This led me to think, how and when do I use Google Scholar vs other "AI search tools"?
Identifiers
- UUID
- 85ee9268-78f6-46f1-969a-08e1fac3ba12
- GUID
- 164998084
- URL
- https://aarontay.substack.com/p/google-scholar-vs-other-ai-search-tools
Dates
- Issued
-
2024-12-15T20:43:00
- Updated
-
2024-12-15T20:43:00