Navigating the Long Context Conundrum: Challenges in Language Models' Information Processing


Solutions to Enhance LLM Performance in Long Contexts
Author
· Qingqin Fang (ORCID: 0009–0003–5348–4264)
Introduction
In the era of AI breakthroughs, large language models (LLMs) are not just advancements; they are revolutions, transforming how we interact with technology, from casual conversations with chatbots to the intricate mechanisms behind sophisticated data analysis tools. Their ability to understand and generate human-like text has set a new standard in artificial intelligence. Yet, amidst the accolades, a crucial question emerges: How effectively do these AI titans manage and interpret the vast expanses of text they're fed?
While considerable research has been dedicated to amplifying LLMs' prowess by expanding their capacity to process extended texts, a gap remains in our understanding of their performance across even longer stretches of text. This gap is not just academic — it's crucial for the real-world application of these models.
Enter a recent, groundbreaking study that casts a spotlight on an intriguing limitation known as the "Lost in the Middle" phenomenon. This phenomenon underscores a significant challenge: LLMs, when tasked with parsing through lengthy texts for information extraction — be it in multi-document question answering or key-value pair retrieval — exhibit a stark sensitivity to the placement of crucial information. Their performance is robust when key details are positioned at the text's extremities but wanes dramatically when these details are ensconced in the middle.
This article is set to unravel the layers behind this phenomenon, probing into the reasons why LLMs exhibit such a marked preference for information placement and what this reveals about their underlying mechanisms. More importantly, it aims to chart a path forward — how can we refine these digital intellects to navigate and process lengthy texts with the finesse and depth they require? Through this exploration, we aim not just to highlight a problem but to kindle a conversation on potential solutions, setting the stage for the next leap in LLM evolution.
"Lost in the Middle" Problem
When LLMs are tasked with processing long texts, especially those requiring the identification and use of contextually relevant information, their performance varies significantly based on the location of the relevant information within the input. The observed pattern is clear: LLMs perform well when the pertinent details are at the beginning or end of the input. However, their effectiveness diminishes when these details are nestled in the middle.
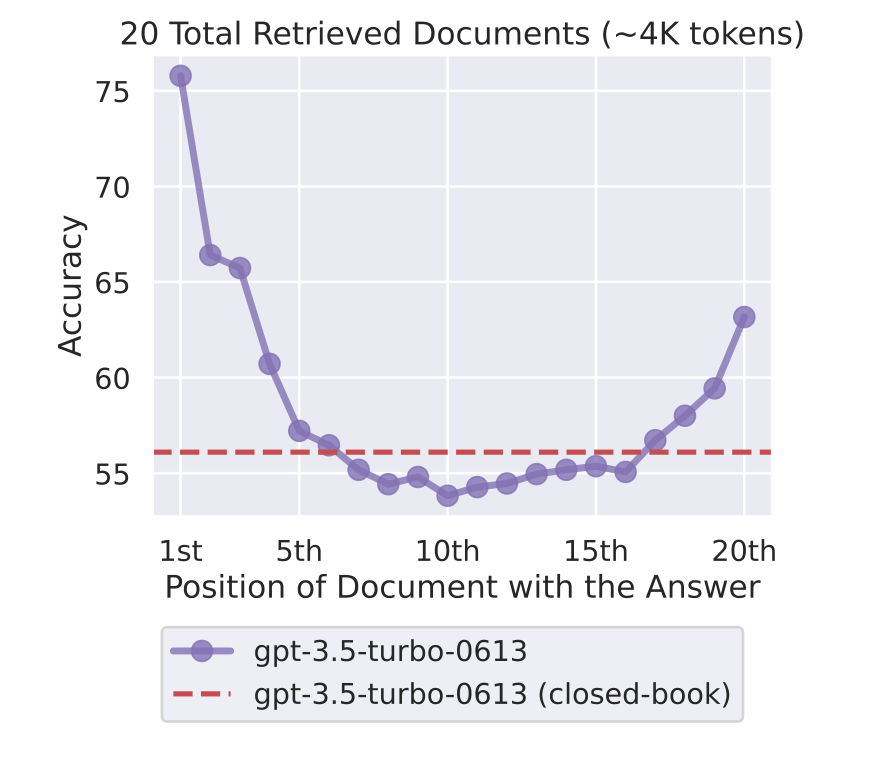
The graph displayed above demonstrates how altering the position of pertinent information within a language model's input context leads to a distinctive U-shaped curve in performance. We can observe that the model's precision is influenced by the location of information, showing a particular challenge in handling sections of text that are not at the forefront or the tail end.
Findings on Experimentation
This behavior was systematically examined across various tasks, such as document-based question answering and key-value pair retrieval. The experiments involved prompts with varying lengths and contexts, positioning the critical information at different points within the text.
In the multi-document question-answering task, the input prompt, as illustrated, included a relevant document capable of answering the question among several irrelevant ones. This crucial document was placed in various positions to test the model's stability.

The following results show that in scenarios with a total document count of 10, 20, and 30, corresponding to token counts of approximately 2K, 4K, and 6K, it was observed that better performance is achieved when relevant documents are located at the beginning or end of the prompt, while performance decreases when the relevant documents are in the middle.
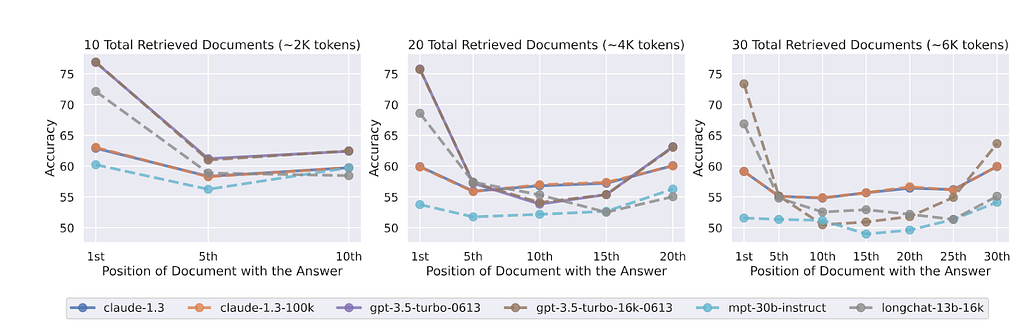
The findings indicated that models performed better when the relevant document was at the beginning or the end of the prompt, with a noticeable decrease in performance when it was situated in the middle. Interestingly, models designed to support longer contexts did not show a significant advantage over their counterparts in this task, indicating a close performance between models with varying context lengths.
In the key-value pair retrieval experiment aimed at assessing the models' ability to retrieve content from long texts, the key needed for the query was positioned at different points within the prompt to test the models' retrieval capabilities.
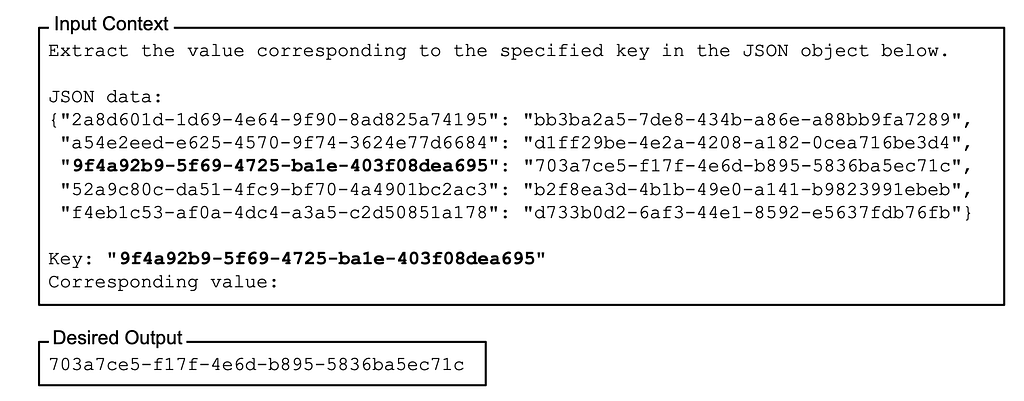
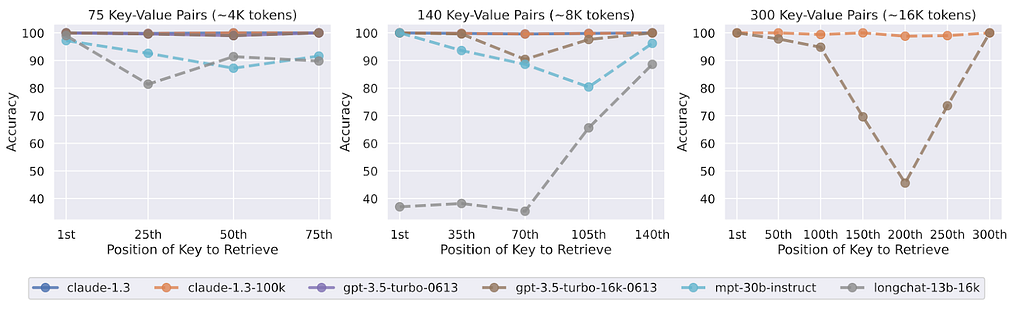
The outcomes suggested that higher-performing models achieved near-perfect accuracy regardless of the key's placement within the text. However, less effective models exhibited a similar trend to the first experiment, where the placement of the key in the middle resulted in lower performance.
Analysing the Causes
In response to the "Lost in the Middle" phenomenon, the researchers delve into potential underlying causes from various angles:
Relation to LLM Model Architecture: The experiments above used decoder-only architectures. The figure below adds the results of two encoder-decoder models (Flan-T5-XXL and Flan-UL2) in multi-document question answering. Similar to the findings above, both Flan-UL2 and Flan-T5-XXL show a decrease in performance when the relevant information is positioned in the middle of the input context, particularly as the input context length exceeds 2048 tokens.

Researchers speculate that encoder-decoder models may better leverage their context window because their bidirectional encoders allow them to process each document in the context of future documents. This ability may help improve estimates of the relative importance of documents.
Effect of Query and Context Information Placement: A comparison between a base LLM and its instruction-fine-tuned version reveals that the "Lost in the Middle" phenomenon is inherent to LLMs, not a byproduct of fine-tuning processes.
Influence of Model Size and Instruction Fine-Tuning: Further analysis reveals that larger Llama models (13B and 70B) exhibit the "Lost in the Middle" phenomenon more pronouncedly compared to the smaller 7B model, indicating that model size and fine-tuning intricately affect the phenomenon's manifestation.
Potential Solution
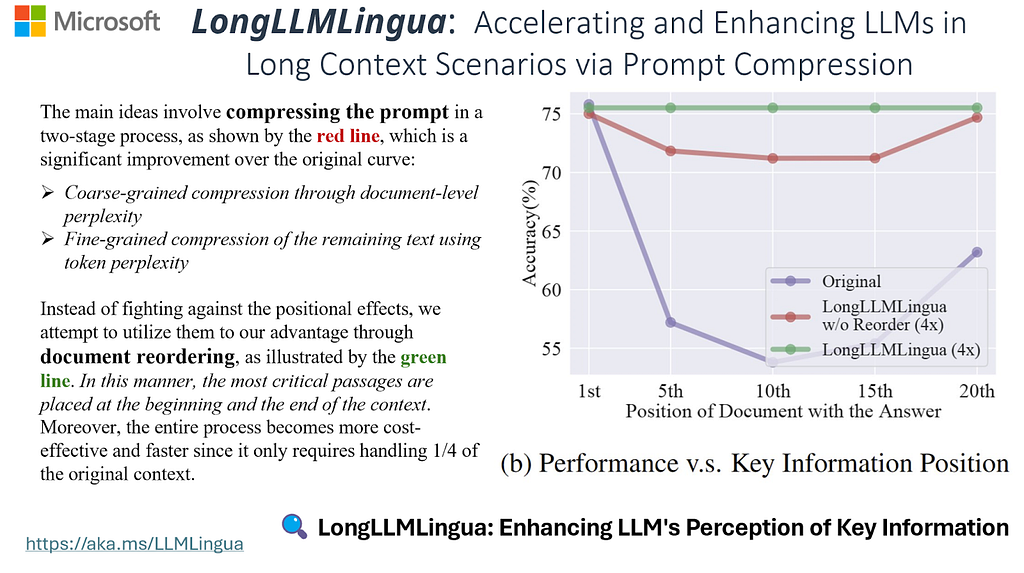
A promising strategy to alleviate the "Lost in the Middle" issue in LLMs is Prompt Compression, as exemplified by the LongLLMLingua approach proposed by Microsoft. This method enhances LLMs' ability to detect key information within prompts in long context scenarios, effectively mitigating the "Lost in the Middle" issue. Particularly beneficial in Retrieve and Generate scenarios, LongLLMLingua can lead to significant cost savings, with up to $28.5 saved per 1,000 samples for GPT-3.5-Turbo (and potentially tenfold more for others), while simultaneously boosting the performance of LLMs.
PARTOR, developed as an advancement of the RAPTOR methodology for Retrieve and Generate applications, significantly enhances the capacity of LLMs to process and understand lengthy texts. As the structure shown, it introduces an innovative methodology that recursively vectorizes, clusters, and summarises text to build a hierarchical tree structure that encapsulates various levels of abstraction.

RAPTOR enhances the way models interact with extensive documents, enabling the retrieval of information across different levels of detail and abstraction. This tree-structured approach allows for more effective integration of information from lengthy documents, which is particularly beneficial for tasks that require complex reasoning and understanding. Experimental results show that this recursive summarisation retrieval method outperforms traditional retrieval-augmented approaches in various tasks. Notably, when combined with GPT-4, RAPTOR improves performance by 20% on the QuALITY benchmark test, especially in complex reasoning-based question-answering tasks.
Conclusion
In conclusion, the exploration of the "Lost in the Middle" phenomenon in large language models (LLMs) underscores the critical importance of understanding how these models process and interpret information within lengthy texts. Through rigorous experimentation and analysis, researchers have identified a significant challenge: the diminished performance of LLMs when tasked with extracting information from the middle sections of documents.
However, this challenge has not gone unaddressed. Recent advancements, such as the RAPTOR model and its evolution into PARTOR for Retrieve and Generate applications, represent promising steps forward. These methodologies introduce innovative approaches to enhance LLMs' ability to navigate and comprehend lengthy texts, particularly through recursive summarisation retrieval methods and hierarchical tree structures.
By effectively integrating information across different levels of abstraction and improving performance in tasks requiring complex reasoning, these advancements hold considerable potential for advancing the capabilities of LLMs. Furthermore, strategies like Prompt Compression, exemplified by LongLLMLingua, offer additional avenues for mitigating the "Lost in the Middle" issue and enhancing LLM performance in long-context scenarios.
In essence, the journey to overcome the challenges posed by lengthy texts in LLM processing is ongoing. As we continue to unravel the layers behind these phenomena and explore potential solutions, we pave the way for the next phase of evolution in language model research and application. Through collaborative efforts and innovative methodologies, we aim to refine LLMs' ability to navigate and process extensive texts with the finesse and depth required for real-world applications, ultimately shaping the future of artificial intelligence and human-machine interaction.
References
- Liu N F, Lin K, Hewitt J, et al. Lost in the middle: How language models use long contexts. arXiv:2307.03172
- Wenhan Xiong et al. Effective Long-Context Scaling of Foundation Models. arXiv:2309.16039
- Parth Sarthi et al. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. arXiv:2401.18059
Additional details
Description
Solutions to Enhance LLM Performance in Long Contexts Author · Qingqin Fang ( ORCID: 0009–0003–5348–4264) Introduction In the era of AI breakthroughs, large language models (LLMs) are not just advancements; they are revolutions, transforming how we interact with technology, from casual conversations with chatbots to the intricate mechanisms behind sophisticated data analysis tools.
Identifiers
- UUID
- 5d88e30a-d8ce-4466-bcb2-3778a09db33e
- GUID
- https://medium.com/p/23d3c48614e9
- URL
- https://medium.com/@researchgraph/navigating-the-long-context-conundrum-challenges-in-language-models-information-processing-23d3c48614e9
Dates
- Issued
-
2024-03-26T03:53:44
- Updated
-
2024-03-26T03:53:44
References
- Liu N F, Lin K, Hewitt J, et al. Lost in the middle: How language models use long contexts. arXiv:2307.03172
- Wenhan Xiong et al. Effective Long-Context Scaling of Foundation Models. arXiv:2309.16039
- Parth Sarthi et al. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. arXiv:2401.18059