
Two different ways of adding open access content into discovery indexes, what are the implications?


It has been over 2 years ago in Jun 2017, where I picked up on the growing trend of library discovery services and Abstract and indexing servicing intergrating open access content into their indexes.
How are things today? Indeed, developments in this area have indeed speeded up and as regular readers of my blog know (older coverage here , here and here ) we have seen the rise of open access (OA) finding services with APIs designed to locate open access versions of paper such as Unpaywall, Open Access button, JISC Core Discovery, Dissem, etc.
Though it is likely these services still find less free to read articles than Google Scholar (even the Unpaywall team admits Google Scholar has a more comprehensive index and other studies seem to back it up), the fact that they exist as API services allows us to avoid relying on Google Scholar which for years was *the* only reliable way to find free to read articles.
These OA finding services are often packaged as browser extensions and as such we have also seen the rise of browser extensions and services that also handle both redirection to paywall and open access copies.
However, It is not just users of such browser extensions that will encounter more open content, traditional and existing library discovery services and Abstracting and indexing databases have also responded to the growing importance of open access and have also started to integrate open access content.
In this blog post, I'm going to discuss the two main ways open access content can be integrated into such system, namely adding "OA as alternative access" vs "OA as a collection", what design choices are available for each method and what implications these choices made will have for librarians.
Two ways of integrating open access content into existing library discovery services and databases
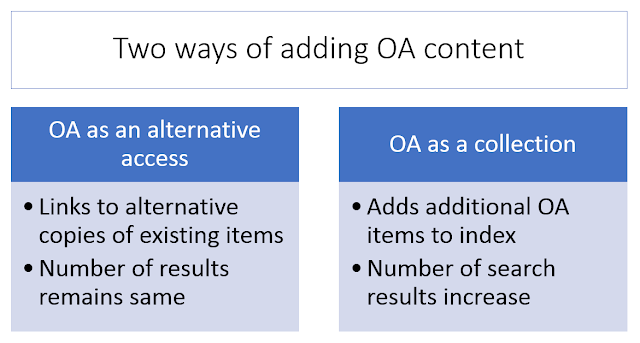
Imagine a typical library discovery services like Summon or Primo or a database like Scopus. They have two different ways of adding open access content.
Firstly they can look at what is in their existing index of peer reviewed journal articles (which typically points only to the publisher final version) and try to provide alternative access to open access versions e.g. via Green OA
This method does not increase the size of their index and will not change the number of results obtained from a search string but merely affects the delivery experience a user gets (but see later).
Secondly, they can actually expand their index by including more open access content and adding the OA source as a collection. This could be as simple as adding (or rather giving libraries the option to add or activate) collections of Gold journals via DOAJ , aggregations of big open access content such as CORE, BASE, OAIster, Unpaywall, 1findr , or smaller more granular collections of OA content e.g. institution/subject repository such as Arxiv. PMC.
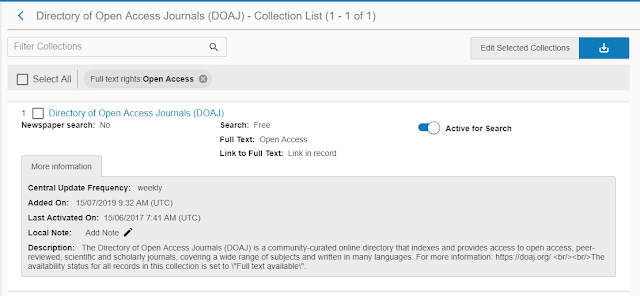
Adding DOAJ as a collection to Primo index
Arguably this second method has always existed in library discovery services, but I would argue that in recent years the number of choices for adding OA collections has increased.
Sidenote: Activating collections perhaps even open access ones in some discovery systems, may have options that do not expose all entries into the index as they may first do a "matching" with holdings before displaying in the results, if such is a case, this is not adding "OA source as a collection" as defined above,
Both methods are not exclusive of course, though abstracting and indexing databases tend to focus on the first method, while Library discovery services like Summon, Primo, Worldcat discovery etc can do both.
I am of the view the first method of adding open content is of greater value, while the second which involving adding OA sources as a collection needs to be considered very carefully.
Due to the prominence of Unpaywall, I'm going to use it has an example of a OA source that can be used in the two different ways to enhance existing Discovery indexes and systems.
Integrating Unpaywall
I think it is to fair say that in the past 3 years, the influence of Impactstory's (now renamed as Our Research) Unpaywall looms large. Short of Google Scholar, I would say that Unpaywall has been one of the most significant developments in making the focus on discovery of open access content.
While I wouldn't go so far as to say Unpaywall as out-googled google it is hard to overstate their impact.
While this may not be true in the sense of Unpaywall finding more (for various reasons e.g. Google Scholar indexing content from ResearchGate which that has a dubious legal status or the fact it crawls the whole web rather than only repositories and journal sites), Unpaywall like many of it's competitors offers an API that allows it to be leveraged for use in library and Scholarly discovery infrastructure not just for discovery purposes but also for analysis purposes.
Unpaywall's integration scope of systems is truly awesome.
Unpaywall data now available via every major academic discovery platform...ProQuest products will join Web of Science, Scopus, Dimensions, OCLC WorldCat, EBSCO EDS, and more in showing #openaccess using Unpaywall! https://t.co/Dlghp0se42
— Jason Priem (@jasonpriem) June 7, 2019
Here's a taste of some of them
Integration with link resolvers - 360link, SFX, Alma uresolver (unofficial) etc.
Called by other OA finding services and extensions - Kopernio, Open Access button, Lean library, Core Discovery
Integration in Discovery services and Abstract and Indexing - Primo/Summon/WorldCat Discovery (announced), Scopus, Web of Science, Dimensions, EuroPMC, Lens.org, ScienceOpen etc
Integration with reference managers - Zotero
Using Unpaywall as an OA indicator & alternative access
In this section, I'm going to discuss how Unpaywall is used to enhance existing indexes with OA status flags and links to alternative copies.
But it might also be helpful to understand the different ways this can be accomplished.
Unpaywall services provides three ways to use their data - Firstly, you can use the API and feed a doi to get back in real time information on what Unpaywall knows about it (including where to find the full text).
This is often leveraged by systems that want a quick, free and easy integration with Unpaywall.
For example many link resolvers (e.g. 360Link integration with Unpaywall and OAbutton, SFX, Alma Uresolver ) do this.
Whenever a record that contains a doi is loaded by a user it will use the API to check unpaywall for any available copies.
For example, this nifty Primo Unpaywall Plugin (below) is embedded into Primo such that whenever a user loads a Primo record in the search result page or item display page, it will automatically call Unpaywall API to check for copies and displays it in real time.
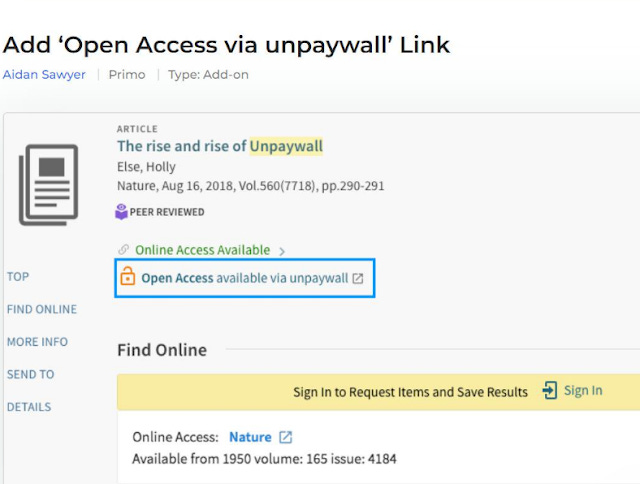
Primo Plugin that integrates with Unpaywall to check for available OA copies
The example above might strike some librarians as a premature use of the Unpaywall API, why check for OA copies before even knowing if a subscribed version exists? After all, the copies Unpaywall surfaces might be earlier drafts compared to the subscribed versions and as such are less desirable.
This is why Unpaywall integration in Link resolvers are more commonly seen. In the example below, the Unpaywall API is only called when the link resolver determines there is no available full text via other sources.
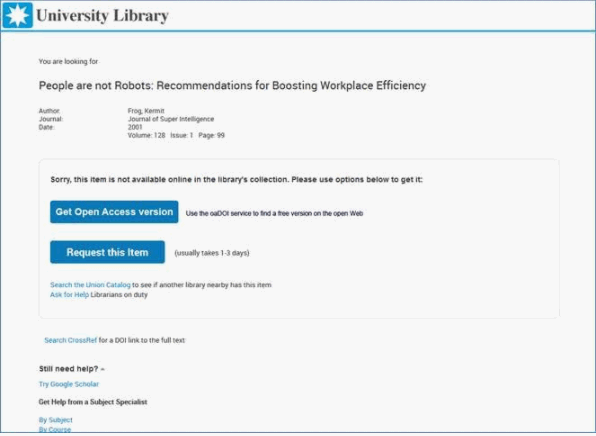
Unpaywall Intergration in 360Link
Some of the API integrations are better than others, for example the ones above, only display a link if the API calls find something , while others like the one currently in Alma , basically always displays a link that you click to check if you can find anything.
Still even with the best API integration, you may run into API rate limits if you are a large institution.
Even if this isn't an issue, the fact that you are calling Unpaywall in real time and not integrating the information ahead of time pre-search, means that you are unable to use the information in advance to allow users to filter results by OA status or show facet counts.
For example, you can't just use APIs if you want to display something like what you see in Web of Science (below).

Web of Science - OA search facet
In such cases you must obviously pre-ingest all unpaywall data into your index by matching your index of records against Unpaywall's database and enhancing existing records with Unpaywall data - in particular links to the OA copies.
As I noted in "Linking to freely available articles - how various databases and citation indexes use unpaywall data " , most databases don't just add every matching item link found in the Unpaywall database
Some pick and choose which links to add.
For instance, while Dimensions and Lens generally add wholesale what they can match against the Unpaywall database, Web of Science only includes those that are Accepted version and Version of Records, while Scopus excludes Green OA.
Data Dump vs Data Feeds
While this is transparent to the user, Unpaywall technically provides two ways for discovery vendors to pre ingest their database.
Firstly, they provides a free data dump/data snapshot of all Unpaywall material (16GB - 85G unzipped) though this is updated only twice a year.
Lens.org for example is a discovery index that uses the Unpaywall data dump (among other sources).
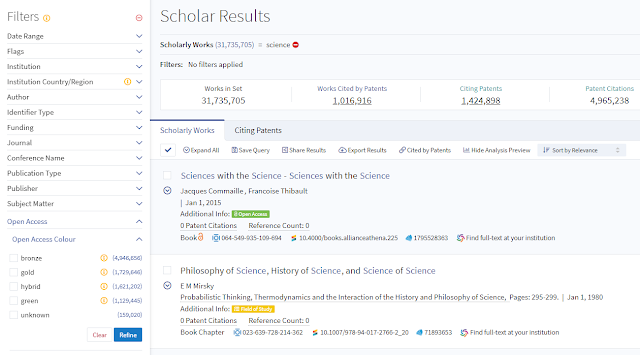
Lens OA facets are partly based on Unpaywall Data Dump
If a discovery vendor wants more up to date data, they will have to subscribe to data feeds from Unpaywall which will give them updates of changes made every week.
You may be wondering why Lens.org doesn't use the data feed and only uses the much slowly updated Data dump? The interesting answer is unlike the API or the data dump which is free, the data feed is a paid service!
This is presumably the option used by Scopus, Web of Science when they announced a partnership.
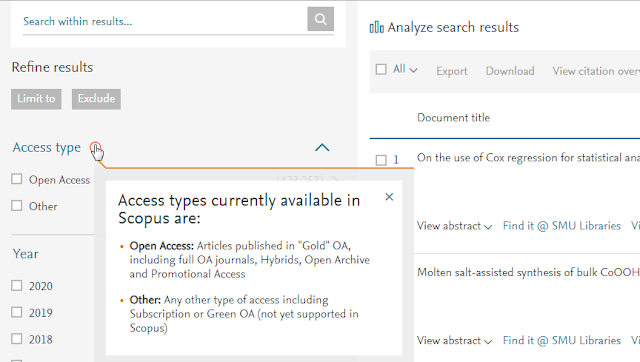
Scopus as a Unpaywall Data feed customer
We also see more recent announcements by OCLC WorldCat Discovery and Proquest which owns Primo and Summon as data feed subscribers.
Of course, one can use both the API and the data feed together or seperately. For instance the already mentioned 360 Link, SFX, Alma Uresolver and this Worldcat Discovery full text link method all worked prior to the companies announcing the data feed partnership
So the upshot of all this is, if you see a search service provide a OA filter and/or facet counts on OA status and it uses Unpaywall, it is using at least the data dump option only or is also a data feed subscriber in which case it will update the OA status on much faster schedule.
Adding Unpaywall as a collection
In most of the examples above, regardless of whether Unpaywall is used as via API, Data dump or data feeds for updates, it is used to enhance the existing index not add to it.
In other words, prior to adding Unpaywall data if you searched for say "History of Singapore" and you got 20,000 results, after the enhancement of Unpaywall data you still get 20,000 results, except for some of the results you may get additional links to free copies.
But what if you not only wanted to provide alternative access to items already in their index but to actually add new additional items? In other words, after this you would find more than 20,000 results because you would find additional items that was in Unpaywall's database that previously wasn't in your index.
This is what I call adding Unpaywall as a collection.
Obviously, for this you can't use the API method, (to be more accurate you could as most APIs do allow you to search by keywords and pipe in the result in real-time, but this would be the federated search method that is out of favour now) but have to use the free data dump method or update via data feeds to get the full data into your index prior to search.
I'm not sure which service actually adds the Unpaywall database wholesale to their index (as opposed to merely checking for OA status) and this is unlikely to be used this way in selective databases like Scopus, Web of Science etc but may be an option in library discovery services.
For example, pretty much every Discovery index integrates DOAJ, PMC as a collection that libraries can choose to activate.
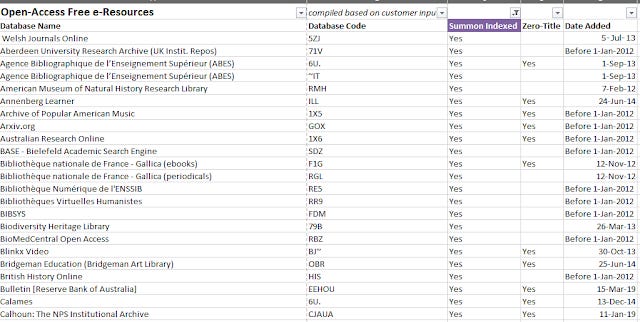
Some OA collections indexed in Summon that you can activate in Summon
I have been told other big aggregators of OA content such as BASE, OAIster, CORE and 1Science's 1Findr (recently acquired by Elsevier) have been ingested wholesale into various discovery indexes such as Summon/Primo , EDS added BASE in 2015 , WorldCat Discovery (see list) or are on wishlists of Primo/Summon.
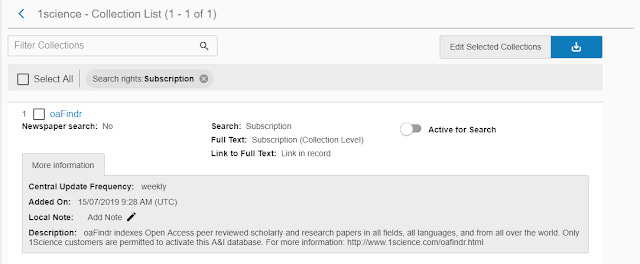
Adding 1Science's oaFindr (renamed to 1 Findr) into Primo index as a collection
In particular, three big OA aggregators - BASE, CORE and Unpaywall have often been hotly desired by librarians to be added to Primo/Summon and at various times were announced to be on the roadmap.
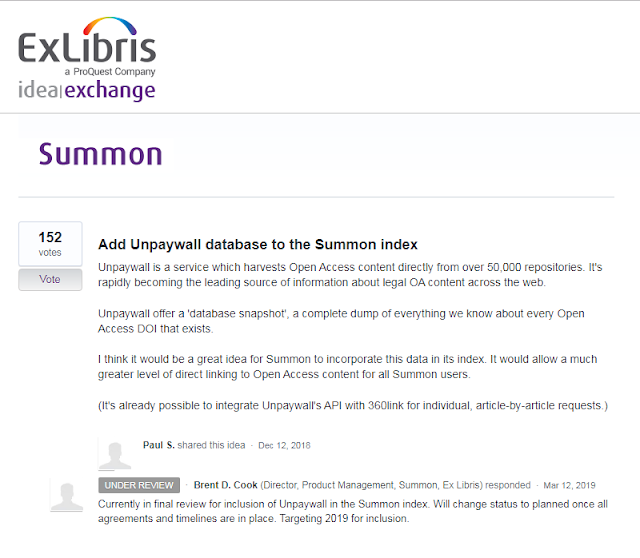
Summon Idea exchange - to add unpaywall database to Summon index
See for example, feature requests for adding BASE, CORE and Unpaywall by Summon/Primo customers.
As I write this in 2019, Exlibris seemed to have ruled out adding BASE and while initially announcing they would indeed add CORE it seems they have abandoned this due to technical difficulties and are now working on Unpaywall.
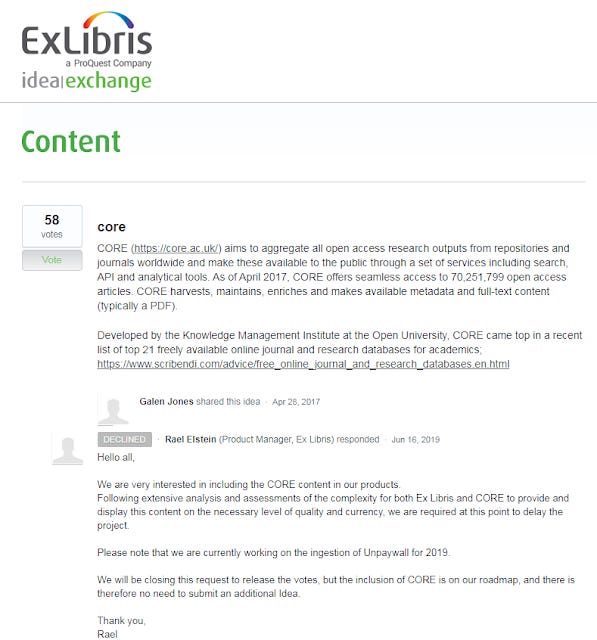
Idea exchange - to add JISC Core to Primo index
The way some of the feature requests particularly that for Unpaywall - "Add Unpaywall database to the Summon index" makes it hard for me to tell if the request is for using Unpaywall to enhance the existing index records with OA status and links or if it is for ingesting the whole database so librarians can add everything as a collection so the whole 20 million or so records in Unpaywall is searchable. I suspect it is for the later (and maybe together with former).
If you have managed to read to this point, you surely appreciate both are very different things!
In fact, I am rather wary about adding big OA collections willy nilly into the Discovery index.
Why libraries are careful about turning on OA sources as collections
Though focusing on the decision to activate available institutional repository (IR) collections in Primo Central Index and not other type's of OA collection, 2013's Open Access and Discovery Tools: How do Primo Libraries Manage Green Open Access Collections? has some interesting quotes by librarians on why they chose not to activate the available Institutional repostory OA collections. As the reasons are often generally applicable to all types of OA collections and not just IR collections, it anticipates this whole section.
Taking the Primo/Summon viewpoint (of which I'm most familiar), traditionally the major problem stopping libraries from adding OA collections into the index (even when available) was that such collections in the past did not properly delineate OA content with those that were not. A very classic example would be institutional repositories where turning on such collections would risk getting a high number of metadata only records with no full text.
With OA aggregations with Unpaywall, CORE and to some extent BASE (which only marks items that it is sure is OA as OA) this problem doesn't exist.
However, given the size of such aggregations, my concern is "flooding" of results. If such collections are offered to be turned on at an all or nothing basis, you are likely to start showing tons of irrelevant material, including foreign language material and disciplines your users are unlikely to use.
In the early days of library discovery many of us adopted a "Turn it all on and let the relevancy sort it out" attitude, but today most of us are aware of the limits of relevancy ranking we have. I have found even including relatively small collections of OA collections such as DOAJ can often have less than desirable effects.
Even given that the relevancy ranking can handle it, do you really want to add every single OA article you can find? Might some be lower quality or even be in predatory journals?
Most importantly adding OA content as a collection is also beset with technical difficulties and risk confusion for users, particularly if the OA content is mostly alternative versions of subscribed content (preprints/post prints).
Using Unpaywall as an example again. As a redirection service to alternative versions, it does not change your index at all, you will still be showing the items you always was showing just with options to variants - organization wise this is clean.
Adding Unpaywall as a collection on the other hand, requires you to do version management with your normal subscribed versions and other OA collections you might have activated (e.g. DOAJ, PMC).
This is very similar to what Google Scholar does, which I suspect isn't that easy, because not everything has a DOI for matching particularly for earlier versions.

Google Scholar aggregates 10 versions of my paper across different sources
While Discovery index vendors like Summon and Primo have experience aggregating metadata records from say Publishers and Aggregators these are ultimately still the same version of papers. I am not aware as yet of their ability to handle different versions like Google Scholar.
My experience so far in the past with turning on OA collections like PMC, DOAJ is that this does not currently happen! This creates tons of confusion to users as they see multiple records of pretty much the same thing appear in their results. Hopefully this has improved since then,
Given the effort of ingesting whole OA collections, I would urge discovery vendors to exercise caution when providing such options.
Of course if you do both, complexity increases even further.....
Implications
If you are a librarian, either on the technical services side or the user facing side and are told your favorite database or discovery service has enhanced it's index with Unpaywall or some similar OA content, I recommend you figure out what exactly this means.
If you find out that what is actually happening is that your database is not actually showing more results but enhancing existing records with links to OA copies , consider the following
What type of OA alternatives are shown? Are we talking only Version of records? Author accepted manuscripts? Preprints? Can we control this?
When are they shown? Are they only shown if the library doesn't have a subscribed version or do they always appear? If the later, what order do they appear in? Can you control the order? Should this be handled in your link resolver, rather than as a separate service in the search results? - Compare how the Primo Plugin does it vs the 360 Link/Alma resolver.
Are there information literacy concerns if your database or discovery index starts showing versions that are not Version of Records?
On the other hand, if you find your database, discovery service is adding or has the option to activate OA as collections, consider the following
What exactly is added? Are they discipline/language relevant? Are there quality controls to ensure that ensure predatory or fake articles are excluded?
Can you control what is added or is it and all or nothing option?
Does the index properly merge all the different versions?
How does this affect information literacy if there is less quality controls on what is included? Do you need to warn users if there is no proper merging of versions? e.g a article title search might get you 4 variants from DOAJ, PMC and Unpaywall copies on top of the Publisher version each as a separate search result.
Conclusion
As OA content starts to gain in importance, librarians have to start thinking on how this interacts with our discovery and database services. My blog post is an attempt to consider these implications.
My attempt to delineate the two different ways of adding OA content, is also echoed somewhat in this recent OCLC talk.
However currently, we still see subscribed content as in the primary position, in time to come when OA content exceeds subscribed content in importance, we might be running into further challenges, but that is still not today.
Additional details
Description
It has been over 2 years ago in Jun 2017, where I picked up on the growing trend of library discovery services and Abstract and indexing servicing intergrating open access content into their indexes. How are things today?
Identifiers
- UUID
- 5d6ef3d7-f44b-4640-b479-dd36d6628324
- GUID
- 164998298
- URL
- https://aarontay.substack.com/p/two-different-ways-of-adding-open
Dates
- Issued
-
2019-07-14T20:46:00
- Updated
-
2019-07-14T20:46:00