
Academic discovery related news that caught my eye - Google updates, scite citation statement search, Zotero plugin Cita, Lean library integrates with EDS, Summon Primo, Clarivate acquires Proquest

Announcement
As mentioned in the last blog post, this blog has been migrated to using follow.it service due to the retirement of Feedburner's email service, and this is the first post since the migration.
If you have subscribed to us via email in the past, hopefully you should be getting this post via email as usual. No followup action is needed.
If you have subscribed to this blog via RSS, the feedburner RSS should still work at least for now, but I highly recommend you switch to Follow.it's RSS feed instead - https://follow.it/musings-about-librarianship-aaron-tay
While you do not need to create a follow.it account in either case, if you do create one you can choose to filter the content you get from this blog either via tags or keywords via email or RSS. You can even choose to receive updates via Telegram!
Introduction
The academic discovery world is constantly evolving and in this post, I will do an update of five new developments in this area that caught my eye recently.
Google rolls out "About this Results panel" - that tells you what is being matched in each search result (news)
scite adds citation statement search and open citations (news)
Lean Library intergates with EDS, Primo and Summon to bring library search to Google Scholar and other parts of the patron workflow. (news)
Cita: a Zotero addon that syncs with Wikidata and does visualization launches (news)
Clarivate acquires Proquest (news)
1. Google rolls out "About this Results panel" - that tells you what is being matched in each search result

About this panel in Google shows you what Google used to match your search query for each result
Discovery can't get bigger than Google, and Google rolled out a pretty significant update last week with enhancements to the "About This Result panel", first introduced in Feb this year. Google states
... if you didn't get exactly what you were expecting to find...Now, there's a quick and easy way to see useful context about how Google returned results for your query, and to find helpful tips to get more out of Google Search
But let me first set the scene.
One of the fustrations of using Google is that you would run a search and get some results surface that made seemingly no sense. For instance if you search for
automobile Singapore Malaysia door
you may get webpages surfaced that do not have all these keywords on the page (neither is it in the webpage url).
Looking at the results Google did not display a "Showing results for...." message , so it does not seem to be overtly overwriting your query.

Google rewriting your search for you with a "Showing results for ..." message
So what might have happened?
Off the top of my head here are some possibilities
The webpage used to have those words when the googlebot was crawling and indexing the page but the page has since changed (hint : check the page cached by Google)
Google substituted the keyword with a synonym or related terms, stemming etc (e.g. automobile with car )
The page was linked from a page using the keyword (or related terms) as a link/anchor text (this is what enables Google bombing)
Google decided that of the multiple keywords you entered one or more are not useful and silently dropped them (typically the last one so the order of your google search is important).
The last by the way is a thing that I've seen Google mention it does in various places such as in it's official course on Power Searching.
In other words except for the first point, it is typical Google trying to be helpful but often in a less than transparent way.
Some ways I know of trying to counter this unwanted helpfulness
Use verbatim mode - this helps mostly with stopping google from replacing your keywords with synonyms and related terms - though the original announcement of this mode suggests it also turns off personalization.
use intext: operator - This supposedly does two things , firstly it forces the keyword to be in the text of the page (remember Google also looks at link text of incoming weblinks) and also prevents google from dropping the keyword - at least according to the official Power searching course by Google.
double quote for a single word to make sure a word is spelled exactly the way we want - e.g. "guarentee"
Despite my best efforts at studying all the official documentation (mostly from the official Google Power searching course), it is still pretty confusing, given that the three methods about seem to overlap a bit and it's unclear what they do or do not prevent.
Wouldn't it be nice to know exactly what Google was "thinking" when it showed each result?
This is indeed what the new "About This Result panel" does.
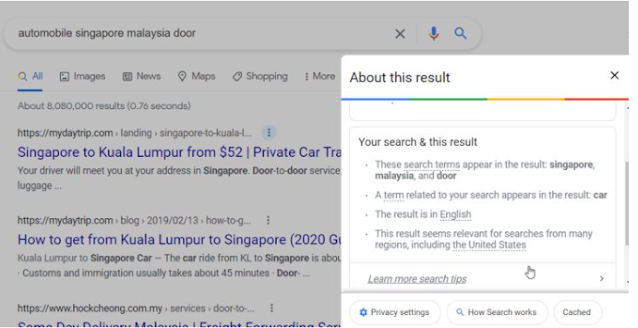
In the example below, by clicking on the 3 dots next to one result and opening up the "About this result" panel, I can see that the keywords singapore, malaysia, door are matched for that result but not automobile.

A Google search and the resulting "About this result" panel for one result
Running the same search with verbatim mode removes such matches as expected.
Instead we see that it seems that Google instead matched a synonyms of automobile - car as we can see the message
"A term related to your search appears in this result:car"
In another example, I tried searching with the keywords
Google Scholar syntax
and one of the first few results displayed this in the "About this result panel".

About this result panel displaying "Other websites with your search term link to this result"
In this case, again some of the top ranked results in Google did not contain all 3 keywords. Specifically the keyword syntax seems to be not matched.
Instead, the "about this result" panel helpfully tells us - "Other websites with your search term link to this result"
I did not comprehensively study this feature, but it seems you do occasionally see other messages, but these are the big three.
Given this powerful tool, one can try to see the effects of verbatim mode , intext: operator , quotes (or some combination of these three) on the results. For example, testing indicates to me that verbatim mode does indeed not prevent Google from silently drop one or more keywords if you have entered several keywords already
No doubt SEO specialists, researchers and librarians are now hard at working trying to use this new feature to better understand Google.
Before you rush out to try
If you are rushing to try to use this feature, do note that it is at the time of writing available only in the US. I had to VPN into the US + incognito mode to see this feature. If you are outside the US, you may not even see the "3 dots". Also, while all regions in the US probably see the "3 dots" and can access the "About this result" panel, some may still be stuck with the older Feb version of this that gives far less information.
Assuming you have access to this feature, this can make you a far more effective Google power user. Knowing for example that a lot of your results are appearing because of "terms related to your search", allows you to better target your search by removing terms with the minus operator.
Or knowing that Google is dropping a certain keyword in a lot of results, would suggest to you to do intext: to prevent that.
A interesting question is whether Google Scholar will eventually get this feature. While perhaps not every feature in Google applies to Google Scholar, a lot of them such as auto matching of related words, dropping of entire keywords do happen and getting more transparency in the results is definitely helpful.
2. scite adds citation statement search and open citations

Citation Statement Search in scite
I've first covered scite more than 2 years ago and have watched it closely since then. As of July 2021, scite's feature set has grown tremendously to the point that it has pretty much what most established citation indexes (e.g. Scopus and Web of Science) have.
For example, it has advanced search with various expected features, saved searches, researcher profiles, dashboards (for journals, funders and institutions) and more. There's even a Zotero plugin.

scite advanced search as of July 2021
Of course scite's unique selling proposition was always about it's use of citation statements and citation context that goes beyond traditional citations which only records a citation relationship and nothing else.
If you are unfamilar with scite, it essentially records the citation statement and uses machine learning to classify citations into 3 types
mentioning cites
supporting cites
contrasting cites (this label has been renamed a couple of times - prior labels included 'refuting', 'disputing' and 'contradicting')
They dub this 'smart citations'.

Citation statements in scite
While this is an interesting way to help researchers understand the context of citations, this requires scite to have the full text of papers they are indexing and while scite has been going beyond open access papers to sign indexing agreements with publishers (e.g. Wiley, Sage , Cambridge University Press are three significant non-stem publishers) as well as preprint servers like medrxiv and bioarxiv and is quickly expanding their coverage, it is unlikely the "smart citations" will soon match the coverage of citation indexes that do only traditional citations.
Edit: The idea of classifying type of citation is also done by Semantic Scholar and even Clarivate Web of Science has a limited beta of a similar feature in the July 22 release. According to the document this "Enriched Cited References" in Web of Science classifies by 4 use categories - Background (also used in Semantic Scholar), Basis, Compare, Discuss
In a interesting twist, scite has taken advantage of the rising tide of open citations and included such traditional itations into scite. This has resulted with over 1 billion traditional citations being added on top of the 849 "smart" citations (aka citations with citation statements).

scite with open citations
I can see the advantages of this move. If users are interested in traditional citation counts , scite now has them and it is typically higher than what is shown in more selective citation indexes like Scopus and Web of Science.
On the other hand, it does lead to more complexity, as scite now includes two types of citations - traditional citations and smart cites.
This in particular means the scite badge and be harder to interpret as there is now a new fourth category to include - traditional citations, on top of the 3 smart citation types - mentioning, supporting and contrasting.

scite new badge includes a new section for traditional citations
This can be quite confusing because the traditional citations are taking into account publications that cite the work.
While the other three smart citations types count citation statements that either mention, support or contrast the work. (The last 5th icon in the badge is for editorial notices).
Since you can have multiple cites from the citing paper to the cited paper, this also means you can have multiple citation statements to the cited work. If you do not wrap your mind around this distinction it can get confusing fast.
scite adds citation statement searching - a promising new search innovation in academic search?
In 2018's - My look at some interesting discovery ideas, trends and features for academic search , I summarised some interesting ideas in the academic discovery space that I encountered and found interesting at the time.
It was also when I first encountered the idea of using the citation statements and sentiment in discovery. In particular, I described my experienced with two tools Sciride Finder and Rfactor.
Rfactor was essentially a precursor of scite, where it would tell you if a paper supports or refutes the paper it is citing. However it was done manually by tagging which limits it ability to scale.
Sciride Finder on the other hand allowed you to search globally for text inside it's citation statements. It called itself a "literature search service on Cited Statements". Sciride covers mostly biomedical content, but even back then I was impressed by how it felt when using it.
All this was prior to learning about scite. When scite came along, one of my wish-list features was for it to have a similar function as Sciride Finder to search globally across all citation statements in scite. Given that scite has way more citation statements than Sciride Finder ever did, it could potentially be even more powerful.
It seems my wish has been granted and scite has started to test citaton statement search, though it is at the time of writing only available via a wait-list.
I have been kindly allowed to test the citation statement search and the results are quite amazing.
I might do a full review eventually, but the key point is this.
The Citation Statement is basically covering claims or findings of papers, by limiting our search within it , we are getting a extremely focused search which at times is even better than an unlimited Google Scholar full-text search. Often it may even immediately give you the answer you are looking for.
Saying something is definitely and always better than Google Scholar is an extremely powerful claim and I'm not saying it here, but I can say for some searches scite gives almost magical results you can't get in Google Scholar.
Because you are searching within citation statements, you can occasionally get the answer you want immediately answered in the citation statement or context. For example scite has been touting the following search to find the effectiveness of the vaccine against the delta variant.
But here's my try instead
google scholar suitable systematic review
The result is seen below

Citation statement search - is Google scholar suitable for systematic review
scite in it's very first result correctly notes that Google Scholar is not suitable as a standalone resource for systematic reviews.
Looking at the sources cited in the citation statement - Bramer, Wichor, et al (2013) , we can see that scite has indeed done very well in identifying the answer and surfacing the right paper.
The equalvant search in Google Scholar unfortunately doesn't do as well, the first result is irrelevant, and while the second result is pretty relevant if you drill in to compare , it's not the best paper to surface since it focuses on 20+ academic search engines and Google Scholar is just one.
Other interesting things I tried with the scite statement search was search for
dataset names (e.g. Finance datasets like Datastream, sustainalytics)
entity names and software (e.g. Vosviewer, Singapore management university) or even github
Common phrases (e.g. "money buys happiness")
Definitions (e.g. Terror management theory is defined as)
P values and common variable names
and much much more including common topical searches like racism in Singapore.
In almost all the examples, I did a head to head test with Google Scholar. This was to test the thesis that a restricted full text search around just the citation statements added value compared to searching full text unrestricted.

Scite citation statement search - searching for datastream
What I found was that often this was indeed true. For example when searching for dataset names , scite statement search almost always gave more focused results than in Google Scholar.
This was particularly true for keywords that were very common and Google Scholar would often match irrelevant papers, due to matches in other parts of the full-text.
Given that when you search dataset names you are often trying to see how a dataset is being used, it is no surprise scite's search which is restricted to only the citation statement can give you more precise results than searching the whole paper (including metadata and full text).
This is not to say Google Scholar results was always worse.
In many scenarios, Google Scholar gave very good results, but you had to go into the paper to look for what you wanted, while scite was often able to give you a quick view by just glancing at the citation statement and context.
For instance if you enter a theory name that you are unfamilar with such as "Terror management theory" into scite's citation statement search you can quickly see how it is defined and applied by many different papers almost immediately.

Scite citation statement search - searching for datastream
Google Scholar's brief blurb/snippets text below the title is often very useful. But because Google Scholar tends to priortize title matches, this can lead to very good results as seen before but less than useful snippets compared to scite.

Google Scholar shows many good results for terror management theory
Of course, there are often cases where Google Scholar gave both good results to look at and the blurb/snippets text highlighted in Google Scholar was almost as useful as scite's citation statement.
In some cases, scite even highlighted the same cited research that Google Scholar gave as top results, however even in those scenarios scite gave a very different view of things.
Currently scite's citation statement search feature still feels very raw. The search is a little slow and the search isn't very exact but I am told this will eventually change. Still what I have seen as made me very excited.
The main drawback I can see about this feature is that it might encourage citation or evidence mining where people search for citations to back what one believes. For example, with some work I managed to find a paper that says there is no good evidence for global warming.
The other possible related drawback I can see if this feature becomes common or popular is that people might get lazy and trust what is stated in the citation statement without checking if the cited paper really says what the citer thinks it said.

For instance in the above example, would people start taking for granted David Gillborn really made the argument as stated in the citation statement of a paper that cited his work and not follow up and read David Gillborn's actual paper?
After all, it is well known that citers can often misinterprete or outright make mistakes when citing/summarising other people's work. I have often run into cases when following up on citations to realize that the cited paper did not say anything close to what the cited papers seem to imply it did.
Of course prior to scite one could do this, but scite's ability to search within citation statements might make this even more tempting to do. User education is needed!
3. Lean Library intergates with EDS, Primo and Summon to bring library search to Google Scholar searches and other parts of the patron workflow.

Lean Library intergrates with Primo
Lean Library one of the so called Access broker browser extensions has recently been building partnerships with companies like Springshare and scite.
They have also done the same in the discovery space tying up with EBSCO to intergrate Ebsco Discovery Search with their Lean Library extension as well as Exlibris to intergrate Summon and Primo.
What they appear to have done is to allow users who are searching within Google Scholar and Google to easily see results for their library discovery service (Ebsco Discovery Service, Summon or Primo) overlaid on the webpage.
I personally think this is an excellent idea, because we know that many of our users particularly undergraduates do not use our library resources (databases, library discovery services etc) as a starting point. Also unlike our more advanced users who often do have the habit of returning to our library resources eventually, most undergraduates may forget that it will usually benefit them to complement their web searching with doing searches in our library discovery service, if not for discovery purposes at least for delivery and access to check what is available to them.
This line of reasoning is not new of course. This blog itself began life in 2009, as I in the waning days of the Library 2.0 movement experimented with bookmarklets, custom toolbars, Greasemonkey scripts, OpenSearch plugins and more.
I was pondering then on the same problem we face today, the dominance of Google and that as Lorcan Dempsey put it "Discovery happens elsewhere". Even if users do not start at our library discovery resources, how can we make it easy for them to get back to us?
Today of course, we have publishers worrying about leakage and competition from Sci-hub and pushing for solutions like SeamlessAccess and GetFTR, but this was before those days.
In Oct 2009, I hit on an idea which I blogged as "Adding your library catalogue results next to Google results using WebMynd ", which was my proposed solution to the problem.

Overlaying results from library catalogue next to Google with WebMynd
WebMynd wasn't a library specific product, Techcrunch described it as such
"WebMynd, a Y Combinator company that launched early last year, has released a new plugin that is looking to streamline the way you search. The plugin, which is available for Firefox and Internet Explorer, enhances the search results on most popular search engines by inserting a handy sidebar with related search results from a variety of other sites"
With the help of WebMynd, I used it to scrape results from the library catalogue of the institution I was working at the time (III's Webopac which had no API) and these would show up in the sidebar, as seen in the image above.
Reading the post, almost 12 years on, it gives me a nostalgic feeling, as this was before the time of Web scale Discovery service and I was still thinking about federation searching , Chrome was still a small upstart browser etc.
I never did pursue the idea further but I believe the idea is sound, and it's good to see the idea reborn in Lean Library's latest features.
4. Cita: a Zotero addon that syncs with Wikidata and does visualization launches
In the past, I've talked about this new Zotero plugin by Diego de la Hera that was being funded by a WikiCite grant from the Wikimedia Foundation but it's finally officially launched!
Back in 2018, when I was starting to think about the concept, uses of open citations in tools like Citation Gecko, I was musings that as nice as open citations was, it was pretty incomplete, could we crowdsource open citations to fill the gaps?
It seemed to me that a reference manager like Zotero could be the place to do this.
I wonder if a reference manager with the functionality of ingesting pdfs to parse citations (e.g. Zotero in plugin) might be useful to double as a way to crowd source open citations which feeds back to a open citations system like OpenCitations.net.
What would the incentive for Zotero users to do this? Well with better open citations, visualization tools that use them (and Citation Gecko among others literature mapping tools that used such data were starting to emerge) would yield better visualizations so it would be win-win.
In 2020, Diego de la Hera then kindly contacted me to inform for me that indeed he was being funded by Wikicite to build a Zotero plugin that would accomplish a lot of this.
The Zotero plugin now called Cita, works with Zotero and Wikidata (as the citation source). With the citation data in your Zotero library, it can create a visualization based on the open source tool- Local Citation Network.
Getting citations data into Zotero

Zotero Cita plugin - context menu options
The main way to get citation data is via "sync citations with Wikidata". If the data already exists in Wikidata you can sync it with your Zotero library. If the data doesn't exist, you can automatically create a new entry in Wikidata and then manually add the information.
Ultimately what you want is for each item in your Zotero library to have data on citations in the new citations tab that the extension creates.

Citations tab in Zotero from Cita
Once you have this in all the items, you want to visualize , you can select them all , right click and select "Show local citation network" which will generate the visualization.

Visualization from Cita
Limitations of Cita

Cita unfortunately only currently supports Wikidata and despite what the context menu says you cannot sync citations from other open citation sources, such as Crossref or OpenCitations Corpus. Given the breakthrough I4OC achieved late last year on getting publishers to open their citations , it is a pity the plugin can't yet draw from Crossref etc.
New as of Sept 2021
Cita 3.0 offers workarounds for importing references from OpenCitations COCI and OCC. In addition if you have the PDF of the article, you can also manually extract references via Scholarcy Reference Extraction API.
Also, during the project proposal, part of the idea was to be able to extract references automatically from the pdf attached in Zotero , however the project ran out of time and this wasn't achieved. Neither can you upload citations using bibtex.
All this is despite the options seemingly existing in the plugin but they are currently non-functional.
Here's to hoping these features will eventually be added.
5. Clarivate acquires Proquest
In May 2021, Clarivate announced they would acquire Proquest for "$5.3 billion, including refinancing of ProQuest debt".
To say this is a big deal feels like a understatement.
Proquest itself is a powerhouse in the industry, between it's content offerings such as content aggregation and databases (including thesis, newspapers etc), Ebook platforms and its strong position in the library systems market via Exlibris and Innovation Interfaces (e.g. Primo and Summon, 2 major discovery services used by Academic libraries, a leading Library Management system - alma, reading list management system - Leganto, Refworks, link resolvers and much more), it is in a commanding position.
Now marry it with Clarivates's stable of products which includes but not is not limited to Web of Science, Publons, Converis, Endnote, Endnote Click (formerly Kopernio) , IP services etc and we have a monster!
I'm already seeing jokes that academic libraries pretty much can now just cut one check to Clarivate and call it a day.
Here's some more background and analysis.
I'm no great analyst on industry consolidation but the obvious thing is we will probably be seeing a workflow play that rivals Elsevier as between Proquest (including exlibris) and Clarivate, Clarivate will have their hooks into almost every part of the researcher workflow.
In fact this new Clarivate can go further as Mukhtar Ahmed, head of Clarivate Science biz notes
We can serve the entire research value chain, early stage and K12 setting, thru postgrad
This is truly mind blowing. One can imagine someone starting off with a Clarivate account taking their first steps into the school system at K12 and by the time he gets tenured 25 years later, Clarivate would know practically everything to know about this person in academia.
Conclusion
The academic space is always in flux, thats why it always remains so interesting.....
Additional details
Description
Announcement As mentioned in the last blog post, this blog has been migrated to using follow.it service due to the retirement of Feedburner's email service, and this is the first post since the migration. If you have subscribed to us via email in the past, hopefully you should be getting this post via email as usual.
Identifiers
- UUID
- d96bb98a-e7dd-4f05-b2d1-a5ff76cd755d
- GUID
- 164998202
- URL
- https://aarontay.substack.com/p/academic-discovery-related-news-that
Dates
- Issued
-
2021-08-02T19:16:00
- Updated
-
2021-08-02T19:16:00