
Fine-tuning GPT-3 for academic discovery - Elicit.org an interesting first attempt

Since I started blogging about GPT-3 and language models, interest in this area has continued to increase.
For example, there have been interesting attempts to see how easily one could use GPT-3 and language models like it to generate disinformation. While I occasionally fancy myself as someone who likes to think about epistemology and how this relates to information literacy, my blog is first and forth most known to cover academic discovery developments (but see a future forthcoming post on my experiments in generating disinformation using GPT-3).
So what can GPT-3 or similar huge language models add to academic discovery?
Pondering: It might be that many of the academic search systems we use already leverage language models in some small way already...According to this paper - "Presently, language models are often not (yet) queried directly for information, but serve to improve query understanding and matching of queries with sentences from documents that have been retrieved using a classical retrieval model."
Since I wrote about GPT-3 last year, the following significant things have occurred
Firstly, GPT-3 is now completely open, there is no waitlist and you can register and sign on immediately to play with it. That said there is a lot of excitement around "OpenAI Codex" which allows you to ask the system to write code, but that is still at the time of writing available only via a waitlist.
Secondly in a Dec 2021 blog post, they announced that you can now fine-tune GPT-3 with your data. They claim
You can use an existing dataset of virtually any shape and size, or incrementally add data based on user feedback. With fine-tuning, one API customer was able to increase correct outputs from 83% to 95%. By adding new data from their product each week, another reduced error rates by 50%.
In fact once you have the training data, they allow you to
customize GPT-3 for your application with one command and use it immediately in our API!
Could one start to fine tune GPT-3 for use in academic discovery? Among some applications listed that were in the early beta on this, they listed Elicit
Elicit is an AI research assistant that helps people directly answer research questions using findings from academic papers. The tool finds the most relevant abstracts from a large corpus of research papers, then applies a customized version of GPT-3 to generate the claim (if any) that the paper makes about the question. A custom version of GPT-3 outperformed prompt design across three important measures: results were easier to understand (a 24% improvement), more accurate (a 17% improvement), and better overall (a 33% improvement).
In fact, Elicit had reached out to me a little earlier to try it out and I was already aware of this tool. So what did Elicit fine tune the model with?
My understanding is they are using Semantic Scholar metadata, including abstracts.
The rest of the post will describe Elicit as it is right now (it is very early stage currently) and the features particularly relating to creation of a table of relevant studies sometimes called a research paper matrix that excites me.

Elicit allows you to create your own tasks with prompts
When explaining language models to novices, people usually start by drawing parallels to the autocomplete you see in any smartphone keyboard. Given a initial sequence of words or characters the language model like your smartphone keyboard will suggest the most probable sequence of words next.
Of course the difference between the simple word prediction models used on your smartphone keyboard and modern advanced language models like GPT-3 is the latter uses far more sophisticated deep learning transformer based methods trained over huge corpus of data
As you probably know, the magic of GPT-3 is that the discovery that once a language model is trained on such a large set of data (around 45TB of text in GPT-3 largest models), it seems to acquire some sort of basic "understanding" of language that it can do "one-shot" or "many shot learning" over many common Machine learning tasks.
A good example of such tasks include Question Answering, Document Summarization, Machine translation, classification tasks and more.
Essentially by prompting GPT-3 with what you want and giving some examples in the prompt it often "understands" what you want and performs reasonably well to generate appropriate responses.
Because Elicit is GPT-3 under the hood, you can actually try to create your own "tasks" in elicit by creating your own prompts and examples and Elicit guides you in a form based way on what you need to enter.

Elicit guides you to create a prompt (click to enlarge)
It also allows you to share those "tasks" you have created with other Elicit users. Below you can see some examples.

Some elicit tasks created by others
I tried some of these tasks and they work fairly well but my focus was mostly on the default task that you see when you logon. Officially it seems to be called "Lit Review: Explore Research Question"
Elicit's default search and performance as a Q&A system

Elicit default search
The default search appears to be designed around a Machine learning task commonly known as question and answering. This is defined as
"the task of answering questions (typically reading comprehension questions), but abstaining when presented with a question that cannot be answered based on the provided context"
In the context of academic discovery, the dream here is that you can ask a question and the system picks out the answer to your question based on what is in the papers.
If you have tried as many new academic search tools as I have, you quickly become jaded by claims that they have new innovative technology that can basically read papers and that will "give you answers instead of papers" and you try and it falls down on even the simplest questions which have clear factual answers.
Even Google with all their budget and know-how only started to do this with a combination of Google Featured snippets and Google's Knowledge Graph for the main Google search but I'm not aware of anything like that for Google Scholar (Google Scholar people if you are reading this, I would love to hear from you!).
So I didn't have high hopes of Elicit.
So let's try - "what is the infection fatality rate of COVID-19?" and the results that emerge look respectable.

Elicit default results for question - "what is the infection fatality rate of COVID-19?"
Elicit like many software of it's kind (Q&A answering) extracts the part of the paper (currently I think restricted to the abstract) that it thinks answers the question. The results while not perfect are decent, you can star the papers that are what you want and it will try to give you more similar papers.
I remember trying out some projects that aimed to answer questions on the CORD-19 dataset, but they were mostly pretty bad. Elicit might be one of the most decent ones I have seen so far.
For each paper you can see the number of cites and even the number that are highly influenced by the cited paper but these are coming directly from Semantic Scholar metadata.
You can filter by type, whether RCT, Review, Systematic Review, Meta-analysis which is good, but nothing ground breaking (I am informed this classification isn't using GPT-3 but is based on some simpler classifer of the text).
So far, you might not be that impressed, after all this is a pretty simple question, with a fairly unambiguous answer and hence is relatively easy to parse out the required answer. I don't disagree,
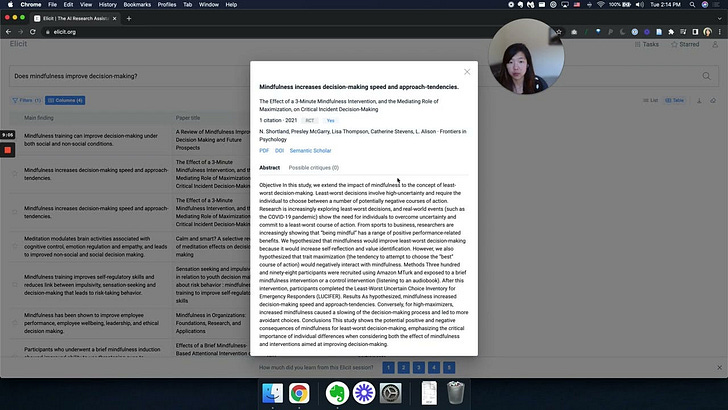
Somewhat more interesting is if you click into each result you might get a "Possible critiques" section

"Possible critiques" section
I'm not sure how this works but I guess this is GPT-3 prompted to "read" citation statements (available via Semantic Scholar corpus) to find possible critiques of the cited paper?
If correct this is an interesting use of citation statements. Semantic Scholar itself does classify citations but into 3 categories (cites background, cites methods and cites results) that do not imply sentiment, so it's an interesting use here.
In fact, "possible critiques" as a category is closer but not quite the same as what scite calls "constrasting cites".
Interesting but I don't blame you if you are not impressed yet.
Elicit's auto creates a table of papers with custom columns - This might be a game changer
What really blew my mind is the table option you can activate on the right side of the screen.
This gives you as you would expect a table or matrix of papers.

Elicit Table of papers generated (click to enlarge)
If you look at the table, you will notice columns for
Claim
Population
Intervention
Outcome
Paper Type (Systematic review, meta-analysis etc)
Year
Citation Count
Answer to question (I think this is only used if the answer is Yes or No)
Clearly people familar with Systematic review will notice the PICO framework columns, but the magic of GPT-3 + Elicit is that you can ask it to add new columns of data.
In this particular example, the "Answer to question" column is blank but let's fix it.
Go to "Add custom column" and add "What is the infection fatality rate?"

Adding custom columns in Elicit table mode
Essentially I think you are asking GPT-3 to read the paper data (which is the abstract currently) and try to answer that question and put it in a new column. See the results below

Not bad at all... You can of course download this table in csv too.
Here's another recent attempt where I asked about sensitivity rates of Antigen Rapid test for COVID-19

What is the sensitivity of Covid-19 rapid antigen tests?
Not bad. But the second result actually gives me the false negative results (FNR) not the sensitivity though you can find it by 1-FNR.
So far you may be thinking okay, this seems promising, but such applications are always tested first and most on Life Science domains As such asking. COVID-19 questions seems to be pretty much a soft ball question.
So let's try questions in other domains
Trying questions in other domains - Is there an Open Access Citation Advantage?
Here, I ask Elicit - Is there an Open Access Citation advantage? This is a boolean yes/no question and this is where the auto generated column of "Answer to the question" comes into use.

Is there and Open Access Citation Advantage? (click to enlarge)
Next I tried to create a new column for the table above, asking it to quantify the OA citation advantage, but results are mixed

Here, I tried playing to create other columns - What institution was the author from? What are limitations of the study?

Leaving aside the fact, that almost non of these studies are Randomised Control Trials and generally don't try to handle the issue of confounding factors, the results look good.
Trying questions in other domains - what affects forecast accuracy in prospectus
Finally we turn our attention to accounting and economics questions - what affects accuracy of forecasts in prospectus? (This has been studied to some degree).

what affects accuracy of forecasts in prospectus?
In this case, the answer is in the intervention column. Then I asked it to add a column based on what country the study was done in.

Added column - What country was the study done in?
Elicit/GPT-3 is able to correctly state the country the studies are done, but draws a blank in two studies shown above. This is because these studies cover multiple countries and the countries were not mentioned in the abstracts.
We end by asking a classic economics question - does minimum wage cause unemployment and also asking it to add a column based on what country the study was done.

does minimum wage cause unemployment and also asking it to add a column based on what country the study was done.
In this particular case , it fails to figure out what country the study was done in 3 cases. Why? Because the study was done in the US and in general when that happens you usually don't mention the country in the paper (or in this case the abstract as that is what Elict uses)! Still in one example, it knew the population was "poorer working Americians" but it did not infer this means the country is US!
Conclusion
Years ago, I blogged about Knowtro, a tool that could extract findings of papers and nicely categorize them into outcome variables, predictor variable, statistical results like p-values etc.

The now defunct Knowtro
There was quite a bit of interest in it, but it was shutdown shortly.
Even today years after I still get occasion questions about it. I guess that is not surprisingly before after all, phds and researchers the world over, would pain-painstakingly collect papers in reference managers like Zotero and export them into CSV and beat the spreadsheet into shape. And this is without taking into account specialized use cases like systematic reviews and evidence synthesis.
Up to recently, this was a pretty manual process. One thing you could use was Scholarcy to create a Literature matrix of results and export them to CSV to help speed things up, but as useful as that would be that would only give you the same standard columns of data that Scholarcy extracted.
The beauty of Elict is that you aren't limited to just predefined columns but you can add new ones as appropriate.
Elicit in an email suggested adding columns like
Where was the study done?
How did they measure ______?
What was the research methodology?
What are the limitations of existing research?
What is the implication?
What did they compare ______ to?
Still one must be careful to trust the results from Elicit as this is new cutting edge technology and Elicit itself warns us to "exercise wisdom" when using it.
In particular there is the worry that language models like GPT-3 will just make up things if it doesn't know the answer. As OpenAI themselves state
Language models like GPT-3 are useful for many different tasks, but have a tendency to "hallucinate" information when performing tasks requiring obscure real-world knowledge
That said OpenAI seems to be making moves to create more "truthful AI" that are less likely to do that and focus on factual accuracy with new models .
In "Aligning Language Models to Follow Instructions" , they talk about how they
trained language models that are much better at following user intentions than GPT-3 while also making them more truthful and less toxic, using techniques developed through our alignment research.
and these new InstructGPT models (including the now default text-davinci-001) outperform the original GPT-3 in many areas , in particular it is less likely to "hallucinate". In fact, user response to them is so popular they are now the defaults.
Still they are not perfect but we will no doubt see improvement.
Another interesting thought is that currently Elicit is working surprisingly well just with abstracts!
As a member of the Intiative for Open Abstracts (I4OA), this clearly shows the importance of the work we are doing but still I wonder, what happens if Elicit/GPT-3 gets its hands on full-text? In theory this seems to have potential for it to be even better at answering questions but the complexity increase moving from abstract to full-text isn't trivial.....
Additional details
Description
Since I started blogging about GPT-3 and language models, interest in this area has continued to increase.
Identifiers
- UUID
- 95ddb5b8-2839-476f-8743-1080718ae24f
- GUID
- 164998193
- URL
- https://aarontay.substack.com/p/fine-tuning-gpt-3-for-academic
Dates
- Issued
-
2022-02-27T17:38:00
- Updated
-
2022-02-27T17:38:00