
6 Surprising things I learnt about Microsoft Academic (I)


Microsoft Academic (first relaunched in 2016) is one of the biggest index of academic content next to Google Scholar. It consists of two major parts Microsoft Academic Graph (MAG), the open dataset source generated by Microsoft by their Bing crawlers and Microsoft Academic - the web search interface created over MAG data.
Microsoft Academic - the web search interface created using MAG.
Since I first started blogging about the Microsoft Academic (just after it was rebooted from Microsoft Academic Search) in May 2017., they have released a ton of information on the detailed workings of this interesting project.
Interested readers should refer to the following
(1) A Review of Microsoft Academic Services for Science of Science Studies
(2) Microsoft Academic Graph: When experts are not enough
(3) A Web-scale system for scientific knowledge exploration - covers generation of Field of Study
(4) A Scalable Hybrid Research Paper Recommender System for Microsoft Academic - related paper and paper similarity API
(4)Blog posts - in particular "Rationalizing Semantic and Keyword Search on Microsoft Academic" covers the latest changes in searching
(5)Microsoft Academic FAQ, Microsoft Academic Graph FAQ
(6)Technical Documents
If you don't wish to go through all that, I'm here to help.
In this two part series on Microsoft Academic I will first discuss the fundemental difference in approach taken by Microsoft Academic compared with general traditional academic search systems.
In particular, for the first part of the series, I will also show how Microsoft academic's claim that it is a semantic search and not a keyword search makes searching in Microsoft academic (the web interface) a very different experience not just from traditional library discovery search systems but even Google Scholar.
While the first part will focus on using Microsoft academic (the search engine), the second part will focus more on the choices made to create the dataset MAG that lies behind the search.
For example, are predatory journals included , if not how are they filtered? Why does the year of publicatons reported by Microsoft academic always seem to be earlier than they should be? How is affiliation handled in MAG?
Given that MAG data is open (made available via ODC-BY) , it is increasingly between used by various academic tools from open discovery indexes (e.g. Lens.org, Semantic Scholar, Scinapse), visualization and citation extraction tools (e.g. VOSviewer, Publish or Perish) or basically any other tool that could benefit from using such data (e.g. Unsub (formerly Unpaywall journals), understanding about the design choices made to create MAG which affect the scope and limitations is important as well.
6 Surprising things I learnt about Microsoft Academic
As we will see understanding how Microsoft academic works as led me to discover the following 6 surprising things about Microsoft Academic that directly affect searching in Microsoft Academic
It matches meta-data only not full text
It is a semantic search more than a keyword search and does not support Boolean operators like OR and AND
It now allows field searching and phrase quotes that bring you closer to keyword searching (new as of May 2020), but with limitations
Microsoft Academic's new "loose semantic query interpretation" will drop terms even quoted ones
When matching terms in "field of study" (Microsoft academic autogenerated hierachical subject system), the subject terms are not "exploded"
You cannot order by citations but only by "saliency" and "most estimated citations" (explanation of what these are)
For a longer version, read on.
How Microsoft Academic differs
Given how Microsoft Academic gets it data by using large scale crawling of the web, it is natural to assume Microsoft academic is pretty much similar to Google Scholar. But reading through and trying to absorb all these very technical documents, it slowly dawned on me that while both might use similar technology to harvest data, Microsoft has taken quite a different approach on processing and presenting the data harvested, which leads to a big impact in how you search in Microsoft academic versus Google Scholar.
That said, Microsoft academic at the broad philisophical level shares similar underpinings with Google Scholar in terms of the belief that large scale harvesting and processing of data is the way to go, which clashes with the traditional library/publisher discovery infrastructure (e.g. Crossref).
How do they differ?
Firstly- there is the belief that human creation of Scholarly metadata (work by Crossref) isn't going to scale and that we should accept the tradeoff of less accuracy but more comprehensive coverage by using bots to extract such data using the latest state of art machine learning and NLP techniques.
"Having to annotate ORCIDs is a mechanical and tedious data processing chore, better left to a machine. Given that scholarly communications are intended for human consumption, it appears more reasonable to challenge the machine to read more like humans rather than ask humans to work harder for the machine." (1)
Secondly, while the first isn't shocking for a big tech company, they also express skepticism on the value of URI/PIDs such as DOIS/ORIDs (though they do seem to extract them in MAG). They argue that such efforts have essentially not succeeded and that many top journals such as Journal of Machine Learning Research (JMLR), Neurips, ICML, and ICLR do not use DOIs or ORCID.
In particular, they point out that JMLR dois are defunct and in fact these IDs are often not as unique as they should be.
"Most importantly, not having DOIs for these publications does not hamper their accessibility. In fact, our data shows these publications are often associated with multiple URLs on the web that can be easily served up by web search engines, making them more persistently accessible to readers than many with single DOIs as their sole presence online. Similarly, the uptake of ORCIDs is also low, which warrants reflection after their heavy promotion for decades...we have observed that individuals would acquire multiple identifiers to partition their publications into separate profiles, defeating the design goal of ORCID being a unique identifier. "(1)
Lastly, they state that their approach of harvesting articles no matter where they are as long as they are scholarly (article-centric) as opposed to the traditional approach of obtaining data at the journal level (centric principle) is more compliant with the currenting thinking espoused in the San Francisco Declaration on Research Assessment (DORA) declaration. A similar argument was made by Google Scholar I believe, but this runs into the problem of handling predatory journals, which they handle by statistical analysis of course (see later).
All in all, the underlying assumption of Microsoft Academic is based on the belief with increasing growth of the academic literature and the inability of publishers , researchers and librarians to keep up hand curating the metadata consistently, we should rely on state of art algorithms to do the work such as disambiguating, assigning topics and learn to rank importance.
In the next section, I will list some of the things about Microsoft academic that surprised me, focusing more on things that have real world impact when you use the Microsoft Academic web interface.
1. Microsoft Academic matches meta-data only not full text
I remember first trying Microsoft academic in 2017 and noticing the number of results were very small compared to Google Scholar, despite early studies showing Microsoft Academic was probably the second biggest academic index after Google Scholar.
Initally it did not cross my mind that Microsoft academic unlike Google Scholar was not matching full text. After all that was one of the biggest advantages of Google Scholar and I assume Microsoft like Google had enough pull they could get publishers to allow their crawlers access to full text.
Even when I suspected it did not and was just matching metadata, I tried testing with unique phrases in open access articles, and there was no match, but could it be because Microsoft academic was interpreting my query in a strange semantic way (more about that later)?
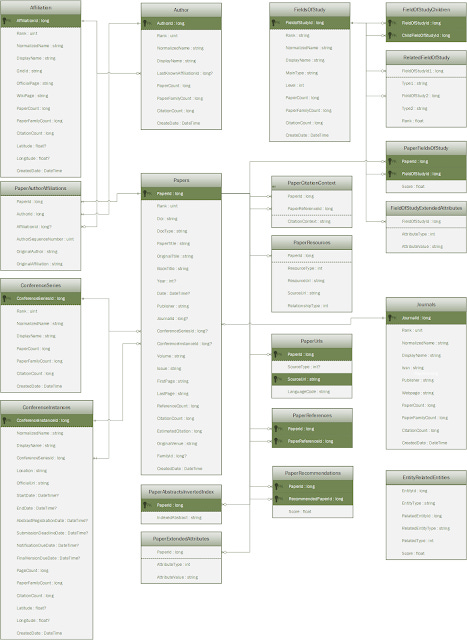
MAG - entity-relationship diagram
However we know MAG only contains information such as
Title
Abstract
Vol/issue/page number
Year of publication
DOIs
Author including author affiliation
Venue (Journal/conference) name
Field of study
References and Citation context
Citation counts, Estimated citation
but no full text and Microsoft academic was just a websearch over MAG data, so logically when you use Microsoft academic (or any search engine that uses MAG data), you are searching meta-data only.
Microsoft Academic had confirmed this fact on Twitter. In fact, they note that Microsoft academic only extracts the entities needed to create MAG (e.g. title, author), including references and citation context and do machine learning over that. They do not even use the full text for Machine learning purposes to auto-generate Field of Study
We're using full text mainly to extract references and citation contexts. We have not conducted concept detection at scale on full text as the results are very noisy. Citation contexts, when used like anchor text for web search, can be really informative.
— Microsoft Academic (@MSFTAcademic) April 17, 2020
The implication if you are using Microsoft Academic to search is that in some sense you are using something more akin to a citation database like Scopus or Web of Science (which does not match full text) than Google Scholar (which matches full text).
2. Microsoft Academic search is a semantic search more than a keyword search and does not support Boolean operators like OR and AND
From the section above, you might be tempted to think you can use Microsoft academic like you use Abstract and indexing databases like Web of Science. To do so would be a grave error, as Microsoft Academic stresses that they are a semantic search engine not a keyword search engine.
The term "Semantic Search" is often marketing lingo (is stemming semantic search?) so I have learnt to ignore it, but in this case ignore this at your peril.
Google Scholar as unpredictable and unreproducible as it is with limitations like the lack of support for wildcards, parentheses, I would still classify as more or less keyword based. You can even do simple Boolean with OR.
This does not work in Microsoft academic!
3. Microsoft academic does allow field searching and phrase quotes that bring you closer to keyword searching (new as of May 2020), but with limitations
Microsoft academic deserves the title "semantic search" due to the multi-faceted ways it applies the latest ML and NLP techniques.
For example it
recognises, extract and disambiguate/group entities such as authors, papers (combining similar versions together)
does concept detection for auto-generating field of study subjects
detect similar or related papers using a combination of embedding and citation-based approaches
learns the "salience" (a kind of importance) of different entities (e.g. author, institution, paper), coupled with reinforcement learning to predict future citations - more on this later
From the point of view of a searcher on Microsoft academic , the most important part to remember is that you are usually but not always (see later) searching an matching on an entity (of there are 6 main types) that is identified by Microsoft and not the keyword string you entered.
Not only that Microsoft academic tries to figure out the "intent" of your query.
MA is different because it employs natural language processing to understand and remember the knowledge conveyed in each document. MA then applies a technique known as semantic inference to recognize the user's intent and to proactively deliver results relevant to the user's intention. (5)
This sounds a bit vague, but essentially it makes a best guess or inference of what the strings in your query is really about. For example, is a string you typing in , referring to a paper title? a topic? a journal/conference? Or perhaps you entered a year of publication?

6 main entities recognised by Microsoft Aacdemic
In a example given by Microsoft themselves when you enter
covid-19 science
in a keyword based search system like Lens.org , Scopus or most academic search engines you familar with, you would get documents retrieved that match those very strings (though these days exact matches are very rare, most would also do stemming or even some form of synomyn matching)
In Microsoft academic it guesses your intent or infers that most probably you are looking for things that are on the topic "Coronavirus disease 2019 (COVID-19)" and in the journal "Science". You can see that this is the first auto-suggestions/query suggestion.
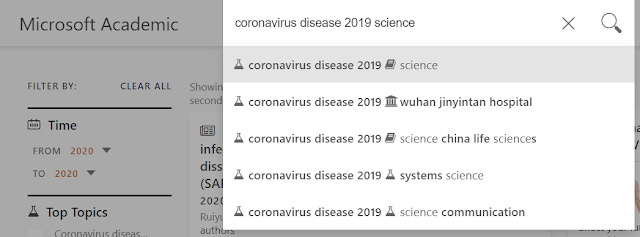
There are of course other interpretions. The second best guess is you are looking for papers on that topic by the authors with affiliation "wuhan jinyintan hospital". The third ranked inference is you are looking for papers on that topic in the journal "science china life sciences". I am not an expert in COVID-19 research but these look like quite reasonable guesses.
You can see that there are icons for topic (the beaker icon), Institution (building icon) and journal title (book icon) and similarly there are icons for other entities like authors, year of publication and titles (see next image)

The auto query suggestions also do autocomplete where they try to match longer strings (see example above for a partial title match) so they are quick way to find half remembered papers or to do searches like (but only if they exist)
If you select any of the autosuggestions it would use only the selected interpretions so in the first example, you would get only papers on COVID-19 from the journal Science. If you do not select any of the auto-suggestions, it will also include other semantic inferences of your query and you get more results.
For the technically inclined, you can call the Interpret Method of the API to see how Microsoft academic interprets the string you enter and it's best guesses but it is beyond the scope of this post to discuss the technical details on how it comes up with these inferences.
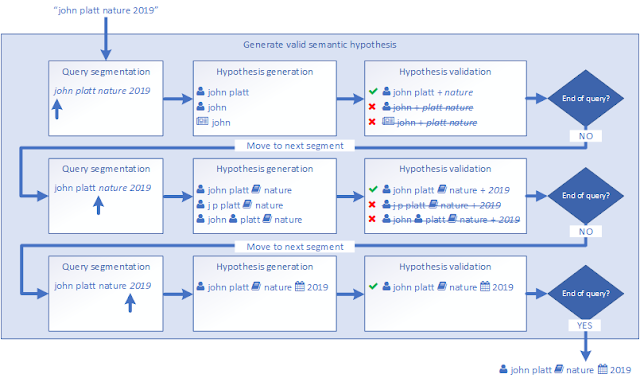
In practice it all works quite well to the point you can enter strings like
z shen h ma k wang 2018 acl
and it can parse this correctly as 3 authors and the conference venue.
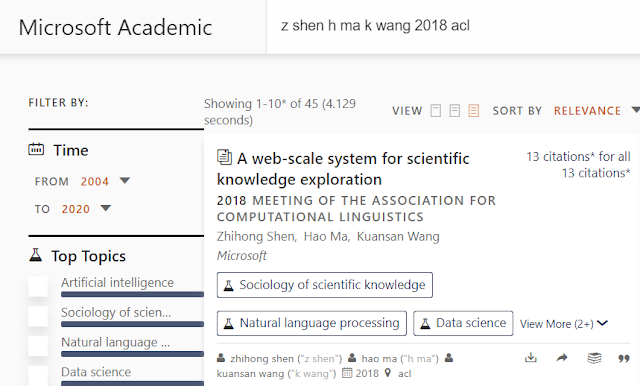
You can see just below each surfaced search entry how Microsoft academic parsed your search query. For the first example above you can see you entered the string ("z shen") and how it interpreted and matched it for the result to appear, in this case the author entity zhihong shen.
This allows you to do matching beyond simple string matching so even if you get the name slightly off or if they are multiple authors with similar name, the system is smart enough to figure out who you are referring to.
Be that as it may, I'm sure a lot of readers of this blog are going - "I want full control - just match the string I typed and don't try to interpret what I'm searching for!". Can you do that?
Sort of - in the latest May 2020 blog post - Rationalizing Semantic and Keyword Search on Microsoft Academic , they introduced new features that moves Microsoft academic closer to keyword searching.
First off, they introduce "quoted values", which allows phrase searching in title or abstract
In other words if you do a search with quotes like
"Deep learning brain images"
It will give you matches when all the words are next to each other (technical term edit distance = 0).
Things to note
It ignores stop words so it will still match - Deep learning of brain images
Normalization still occurs (this seems to be mostly removing case sensitivity , but singular vs purals seems to get you different results? Amercian versus British spelling?)
matches only phrases within the same field
But you can also do multiple quotes in one query, for example
"Deep learning" "brain images"
will work as you expect.
You can now also do specific field searches and combine them with quotes
For example the following works
abstract: "heterogeneous entity graph"
to match strings in the abstract and you can do the same for affiliation, author, conference,doi, journal,title,topic and year using the same syntax

Microsoft academic supported field specific syntax
You can also combine multiple fields in the same query
title: "microsoft academic" abstract: "heterogeneous entity graph"
The same limitations with regards to normalization, stop words apply as well.
This is a major move to push Microsoft academic closer to key word searching (the above limitations don't seem that serious) but let me talk next about the last feature that puts a damper on those of you wishing to use it like a keyword search engine.
4. Microsoft Academic's new "loose semantic query interpretation" will drop terms even quoted ones
Some of you might be thinking with the introduction of quotes and field searching, Microsoft academic might be tranformed into basically a keyword search engine.
Unfortunately this is not true.
One of the main purposes of Microsoft academic is to help the user even when they don't quite enter the right keyword.
They give an example of someone entering
"heterogeneous network embeddings via deep architectures"
and getting nothing because the title is actually "Heterogeneous Network Embedding via Deep Architectures" (note the correct title is using embedding in singular not pural form).
Most search engines would handle this just by stemming but Microsoft academic is a semantic search. They introduce what they call "loose semantic query interpretation".
"To put it simply, we've changed our semantic search implementation from a strict form where all terms must be understood to a looser form where as many terms as possible are understood." (4)
What does "terms understood" mean?
Remember how I said in the above section as you enter terms into the search they try to interpret your term as an entity so for example Tay might be an author, National University of Singapore might be a institution?
The older version strictly only pulled out results that could match these interpreted terms.
The new version on the hand when it detects that there are "queries with full-text matching intent" it switches to a loose matching where it tries to match as much as possible and rank them in order of amount matched.
The blog post has a very detailed example of how it works, but the upshot is, as you look down the list of results, you will start to get queries where terms are dropped!
Below shows an example of a result like this. The search query
library discovery ebsco
generated 343 results, and the first few results match all termed searched , such as this one.
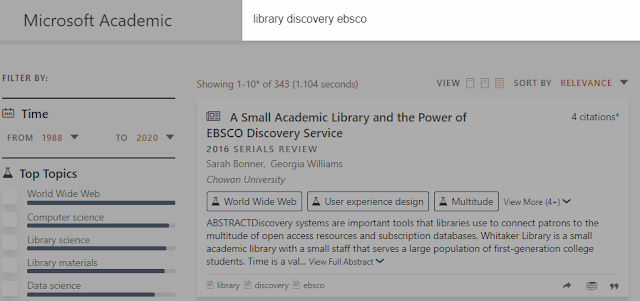
Result appears because it matches all terms in title or abstract
However, if you look at the tail end results you get some results like this
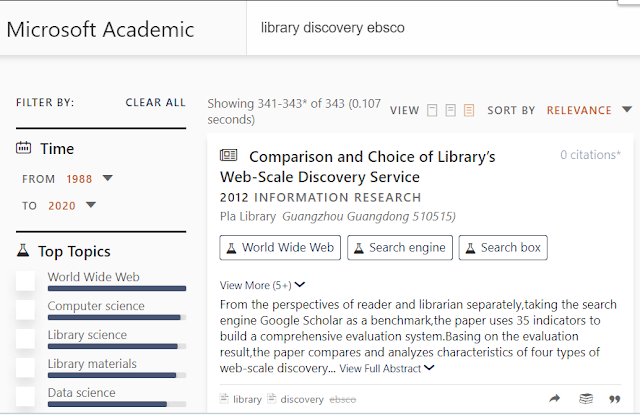
Microsoft Academic search result that matches library, discovery but not ebsco (crossed out)
Helpfully, below the search result, you can see it is able to match library and discovery in title or abstract but the word ebsco is crossed out, showing it is not matched.
In keyword matching terms this is called a Soft AND that you sometimes see in Google.
You might be thinking , I'll just add quotes around the term then to force it to appear. Unfortunately this doesn't work either.
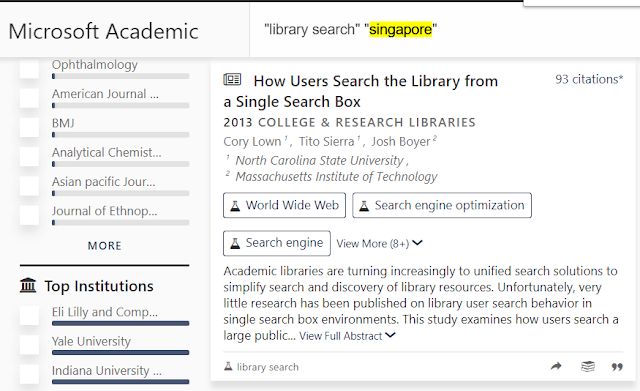
Microsoft Academic search result that ignores matches for the word Singapore even quoted
This is confirmed by the blog post that says
"A quoted value is treated as a single query term and can be dropped accordingly based on the new search algorithm"
As well as a Tweet from Microsoft when I asked for confirmation
We're using a statistical algorithm to juggle between the two ranking functions for keyword and semantic matches. If the heightened penalty of dropping terms in quotes is still outweighed by the joint relevance of the search results, the algorithm can still choose to drop them. https://t.co/Yd9PJtc62F
— Microsoft Academic (@MSFTAcademic) May 22, 2020
As users of keyword searching generally want predictable searches, this puts a big dent in their hopes. I've argued in the past that while more fuzzy type matching in terms of stemming, even synoymn matching is more or less accepted now, dropping terms is not.
Then again Microsoft academic will never a tool designed for such precision searching.
If you want more predictable keyword searching try Lens.org and restrict the search results to the identifer MAG. Given that Lens.org has some time delay in importng new MAG results, another option would be to try searching Microsoft Academic via Publish or Perish via the API?
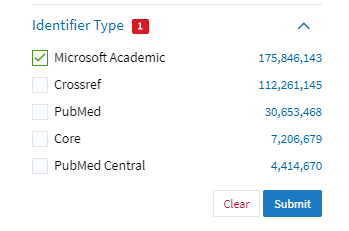
An alternative way of querying MAG data, using Lens.org with identifer restricted to Microsoft Academic
A side note is the blog post suggests with loose semantic interpretion , results can differ from session to session leading to reproducibility issues
.. factoring in variables such as query complexity and service load, the results generated from a fixed timeout where terms are more loosely matched (aka the result "tail") could vary between sessions. However because the interpretations with highest coverage are generated first, the results they cover (aka the "head") are very stable.
5. When matching field of Study, the subject term is not "exploded".
I will discuss a lot more about field of study in part two of this series on Microsoft academic, but it is essentially a auto-generated list of subjects generated using concept discovery. You can think of it as something similar to LCSH or MeSH but autogenerated.
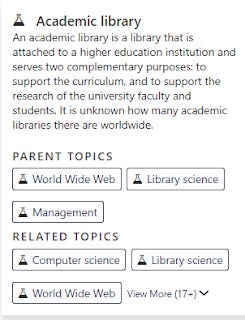
In one aspect though it is similar to MeSH but not LCSH, in that the concepts/subjects generated are arranged in a hierachy (6 levels).
So for example "Academic Library" has parent concepts of "Library science", "Management" and "World Wide Web".
While "Library science" itself has "Computer science" has the parent concept.
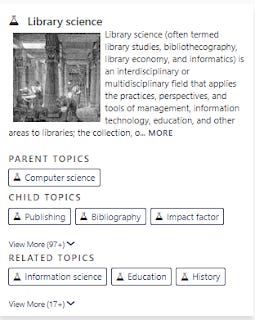
In terms of searching using field of study, the main thing to notice is searching using it , does not automatically include papers that use the narrower child concept.
So if you were hoping that searching for "Library science" field of study would get you papers that were tagged with a child concept of "Academic Library" (but lacking a tag of "Library science"), you will be disappointed.
Neither can you make the search interface "explode" the term to match child concepts. As at the time of this post, I know of no way to do this.
6. You cannot order by citations but only by "saliency" and "most estimated citations"
Saliency is an important concept in Microsoft academic, but what is it?
MAG computes saliency using reinforcement learning (RF) to assess the importance of each entity in the coming years. As MAG sources contents from the Web, saliency plays a critical role in telling the difference between good and poor content. The RF algorithm is programmed to predict future citations. (https://www.microsoft.com/en-us/research/project/academic/articles/microsoft-academic-resources-and-their-application-to-covid-19-research/)
A simple way to understand it is that saliency is roughly the "importance" of the item and Microsoft calculates saliency not just for papers but also other entities in MAG, including author, journal (called venue), affiliation, topic etc.
It's beyond my meager understanding of machine learning to fully understand or explain how this saliency is done but I gather that saliency is essentially a Eigencentrality Measure (similar to the more familar Google pagerank or Eigenfactor/article influence or SJR) but unlike eigenfactor or SJR which constructs a network using the same type of entity (aka Homogenous network of webpages or papers), saliency is done over a hetrogenous network i.e a network of articles, authors, journal titles etc.
"to account for the heterogeneity of the network, MAS uses a mixture model in which the saliency of a publication is a weighted sum of the saliencies of the entities related to the publication. By considering the heterogeneity of scholarly communications, MAS allows one publication to be connected to another through shared authors, affiliations, publication venues and even concepts, effectively ensuring the well-connectedness requirement is met without introducing a random teleportation mechanism."
One of the advantages of calculating a saliency for every entity and not just paper is that Microsoft academic is able to do a ranking of journals, conferences, authors etc. (Side note the hetrogenous network also means you can have multiple "senses" of how two entities are similar eg two institutions can be similar if they have papers that tend to be in the same venue, or if they have many co-authors that collobrate).
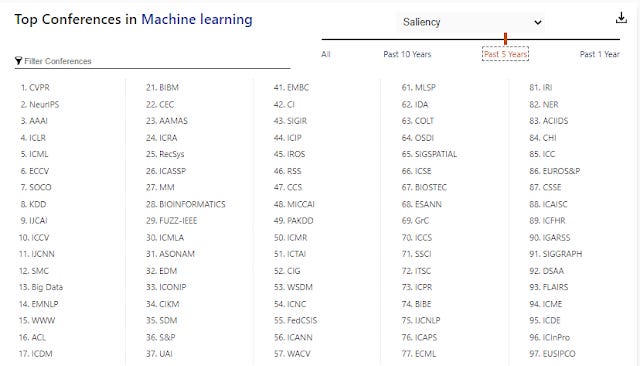
Top ML conferences ranked in Microsoft Academic by salience
Because the "importance" or saliency of an item is likely to vary across time, they employ reinforement learning to learn the right weights (e.g decay rates). This is done by
using the data observed up to 5 years ago to predict the citations of the recent 5 years
and this can be done in time steps of 2 weeks.
It is important to note that saliency measures both impact and productivity just like H-index and Eigenfactor. As such they also calculate a publication size normalized variable of this called "prestige", so that bigger entities (journals/authors/institutions with more papers) can be more fairly compared with smaller ones.
Now they you roughly understand saliency and estimated citations, you might be wondering why not just use actual citations?
Firstly citations is a time lagged indicator, so for new publications, you may not see the full impact until years later. For example with the salience metric, Microsoft academic was able to quickly notice and learn papers on COVID-19 were likely to be important and rank them high even before papers on them had a lot of citations using search terms like chronavirus china.
Secondly, as already mentioned by calculating saliency of not just papers but authors, and even venues like journals and conference one can not only rank them, but one can try to use it to handle the problem of excluding dubious sites. More on that in part two of the series.
Why then not just use "saliency" instead of "most estimated citations" or vice versa. It seems while saliency agrees with estimated ciations rankings 80% of the time, there can be disagreements 20% of the time due to effects of other non-citation factors.
Although future citation counts are the target for best estimating the saliencies, they only agree on the publication rankings roughly 80 percent of the time, demonstrating the effects of non-citation factors (Figure 3) in the design of saliency. In contrast to citation counts, saliencies are sensitive to the venues, the authors, the concepts, and the recencies of the citing sources.
We will have a lot more to talk about saliency in part two of this series
Bonus
Microsoft academic does include indexed works as well as cited references.
If there isn't a View Link or View PDF option, it means that we know about a paper because it has been cited by another paper in the graph, but we have not yet located a copy online.
Conclusion
This concludes part 1 of the series on "Things that surprised me about Microsoft Academic". The next part will focus more on properties of the MAG data which will apply not just to Microsoft academic users but potentially also to users of other tools that use MAG data.
It will focus more on how data like author affiliation, field of study and year of publications are extracted and combined to generate MAG data and the implications on how this affects the data produced.
Additional details
Description
Microsoft Academic (first relaunched in 2016) is one of the biggest index of academic content next to Google Scholar. It consists of two major parts Microsoft Academic Graph (MAG), the open dataset source generated by Microsoft by their Bing crawlers and Microsoft Academic - the web search interface created over MAG data. Microsoft Academic - the web search interface created using MAG.
Identifiers
- UUID
- b3be99a3-e0b3-4eab-ab22-91ff45b16d02
- GUID
- 164998269
- URL
- https://aarontay.substack.com/p/6-surprising-things-i-learnt-about
Dates
- Issued
-
2020-05-24T23:52:00
- Updated
-
2020-05-24T23:52:00