Pubblicato in Andrew Heiss's blog
Autore Andrew Heiss
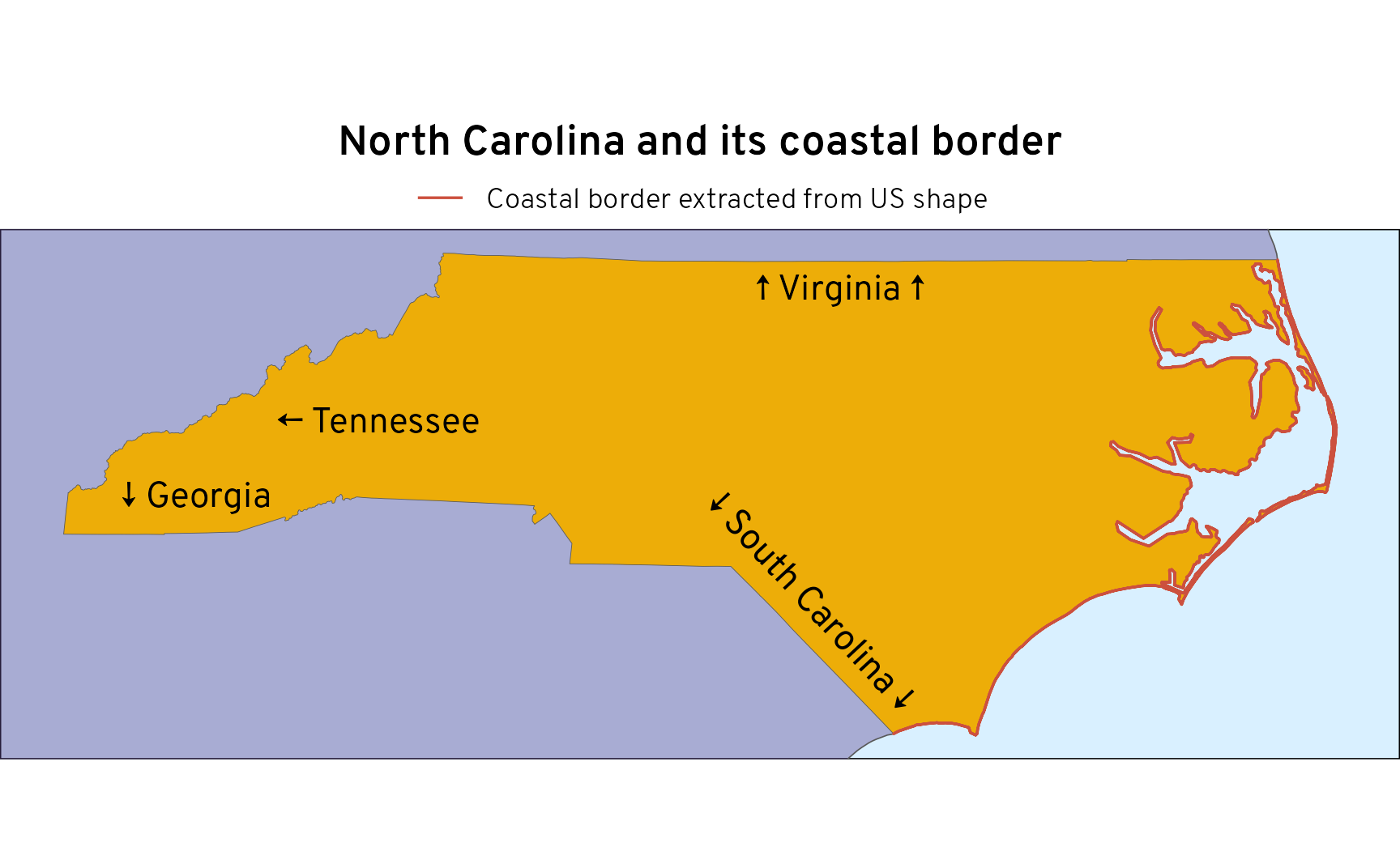
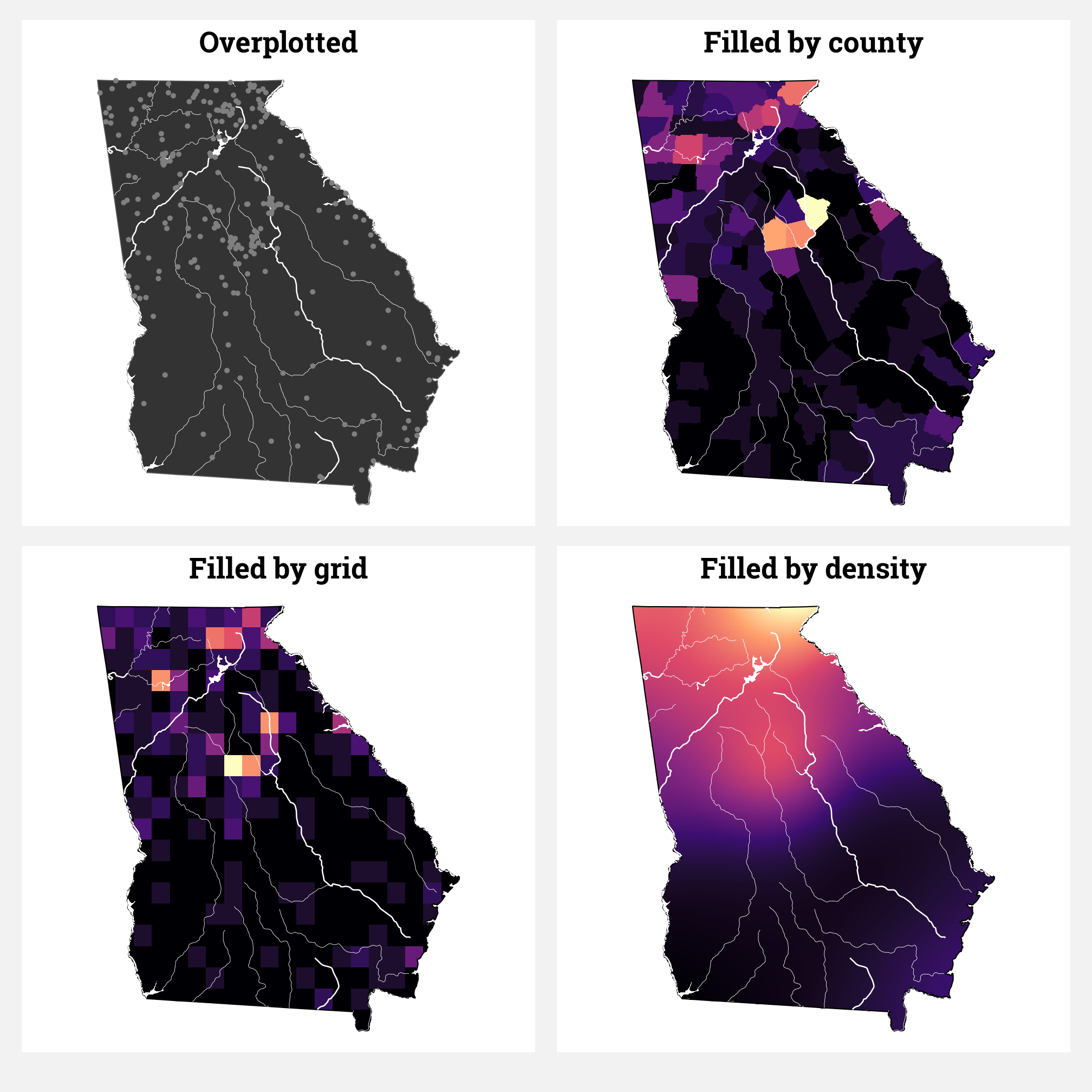
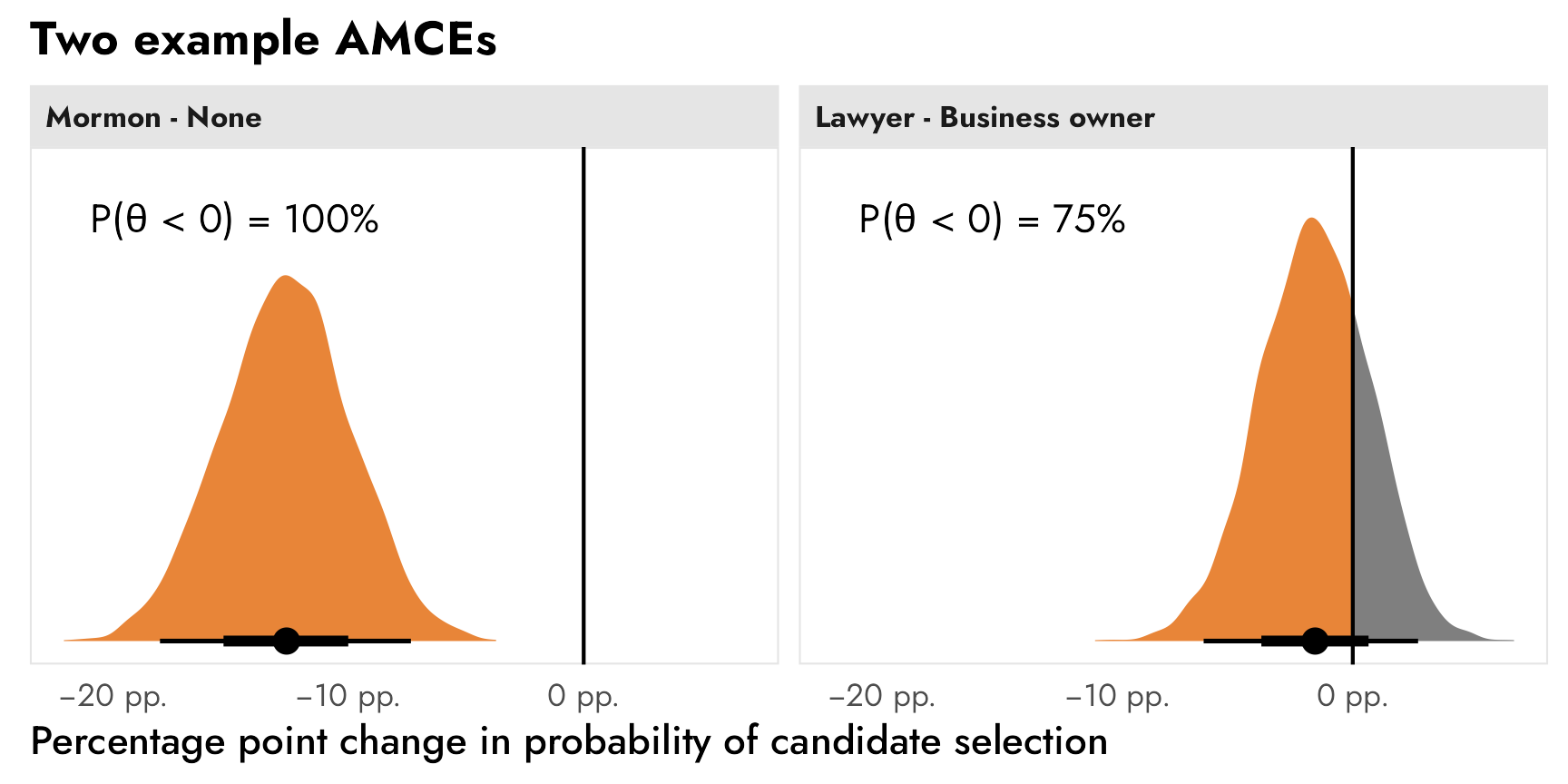
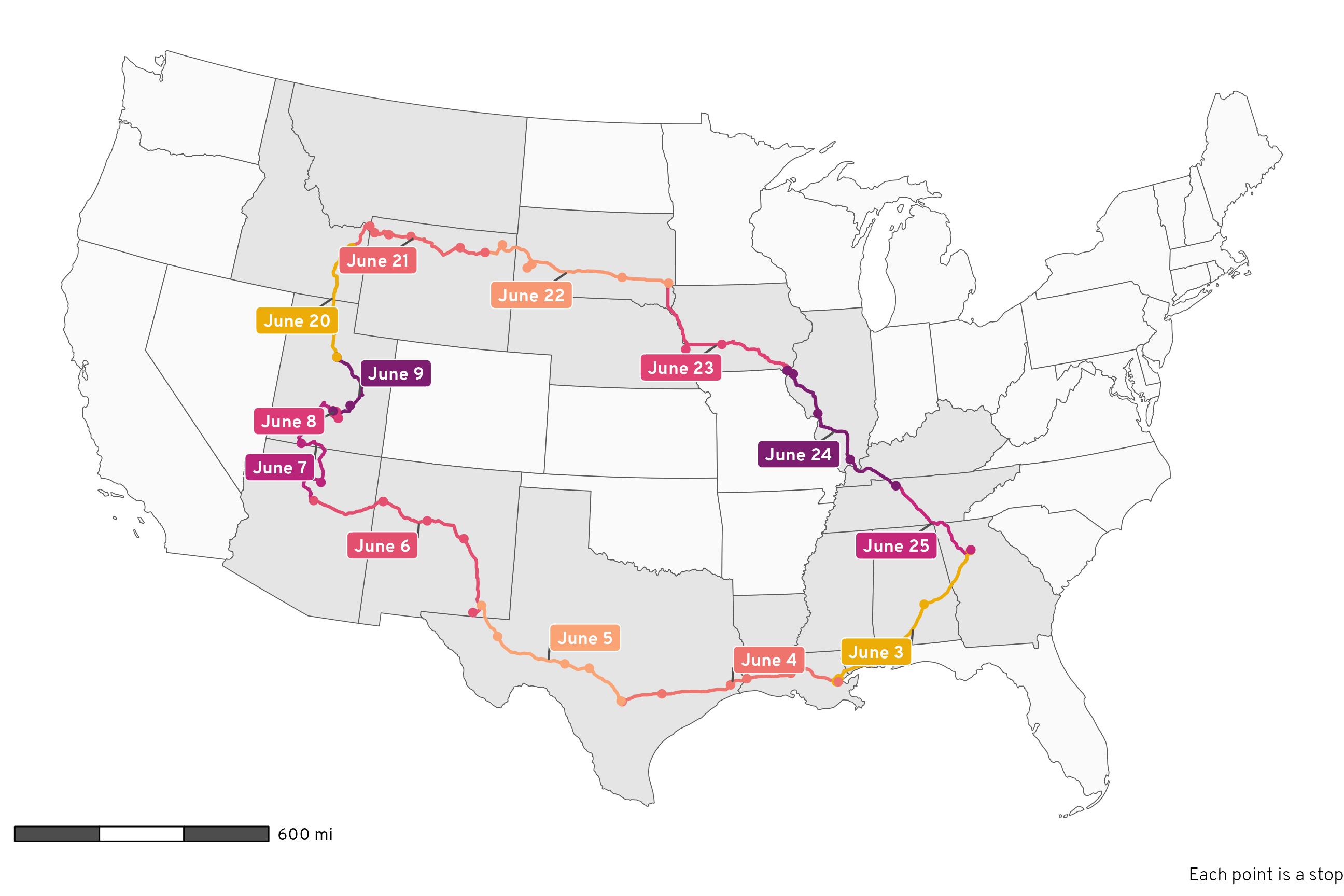
A few days ago, my wife, a bunch of my kids, and I were huddled around a big wall map of the United States, joking about the relative unimportance of Rhode Island, the smallest state in the US. It’s one of the states I never ever think about: …and it’s just so small . Amid the joking, my wife came to Rhode Island’s defense by declaring that even though it’s so small, it has one of the highest proportions of coastline to land borders.