Publicados in Andrew Heiss's blog
Autor Andrew Heiss
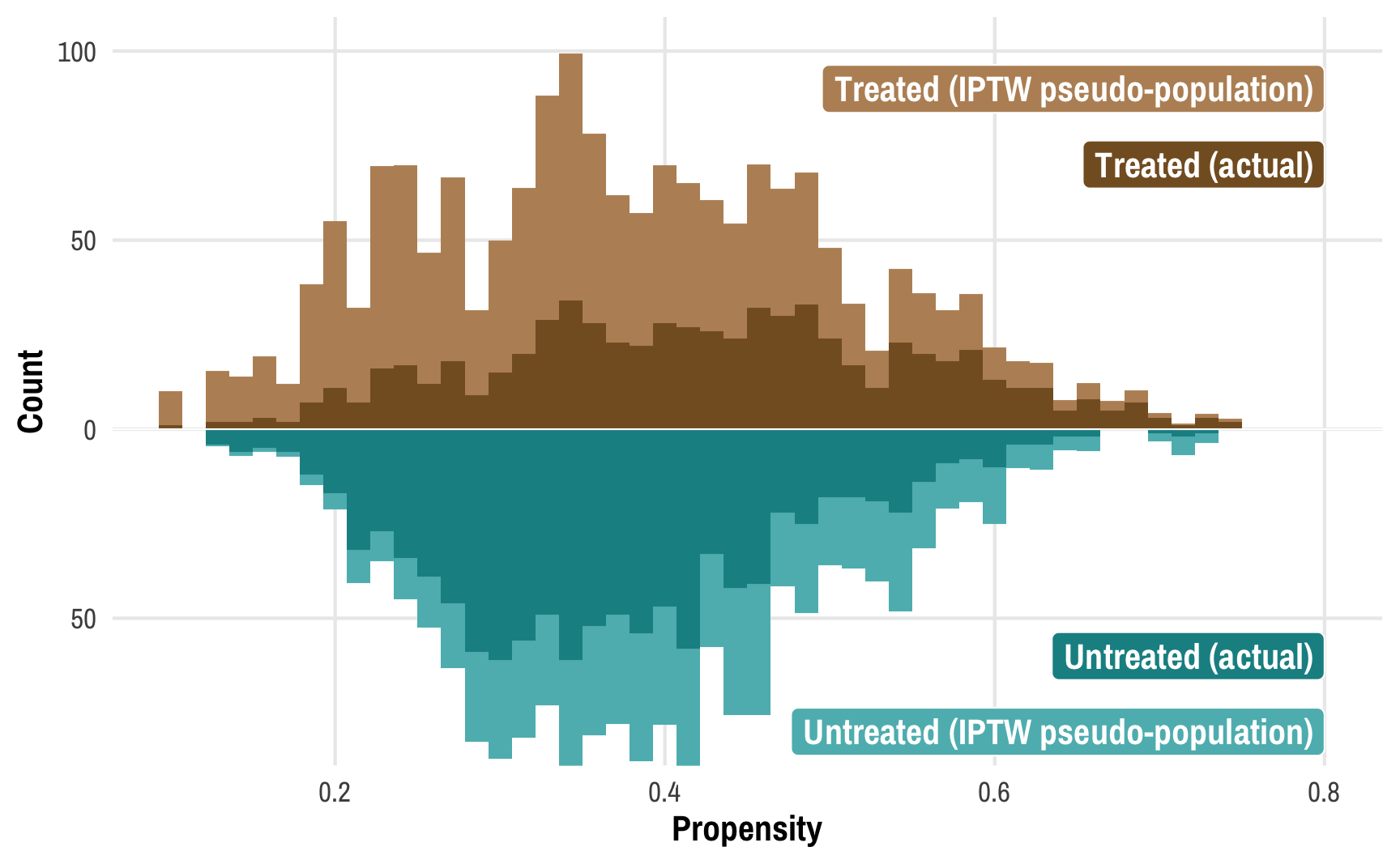
This post combines two of my long-standing interests: causal inference and Bayesian statistics. I’ve been teaching a course on program evaluation and causal inference for a couple years now and it has become one of my favorite classes ever.