Publicados in Economics from the Top Down
Autor Blair Fix

I’m sick of the AI hype and scaremongering. The idea that AI could take over the world is laughable.
I’m sick of the AI hype and scaremongering. The idea that AI could take over the world is laughable.

This is Ralph. How tall is Ralph? It seems simple, you could just hold a ruler up to the screen. But when you look at the ruler and use it to measure Ralph, are you actually measuring Ralph , or are you measuring the ruler and using that as a proxy ? How accurate is your measurement? Are you including fur in the measurement? What if Ralph were to stand on his hind legs, like a mighty bear — how tall would he be then?

Over at the work blog, I’m discussing what knowledge means for large language models (LLMs), and the ways in which we can leverage this knowledge dividend for better inference. Read the full post here.
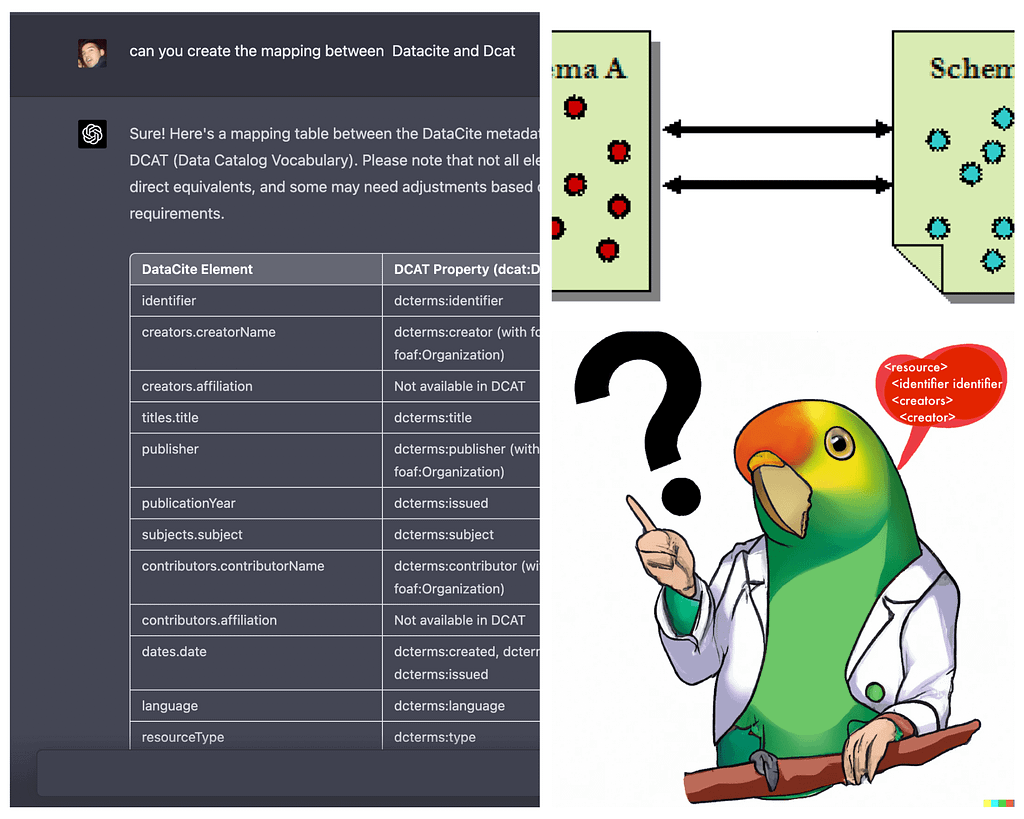
Picture, if you will, the labyrinthine world of academic information management, where metadata schema mapping serves as a vital underpinning for the exchange and intermingling of data across diverse platforms and systems. This arena has long been dominated by the venerable metadata schema crosswalk, which, though serviceable, has begun to show its age.

There’s a notion in artificial intelligence known as Moravec’s paradox: it’s relatively easy to teach a computer to play chess or checkers at a pretty decent level, but near impossible to teach it something as trivial as bipedal motion. (Hassabis 2017) The sensorimotor tasks that our truly wonderful brains have mastered by our second birthday are much harder to teach a computer than something arguably as ‘complex’ as beating a chess grandmaster.

In a recent paper that has attracted the interest of popular media as well, Fabio Urbina and colleagues examined the use (or rather, the abuse) of computational chemistry models of toxicity for generating toxic compounds and potential chemical agent candidates.(Urbina et al. 2022) Urbina and colleagues conclude that Urbina, Fabio, Filippa Lentzos, Cédric Invernizzi, and Sean Ekins. 2022.
Markus Strasser (@mkstra write a fascinating article entitled "The Business of Extracting Knowledge from Academic Publications". His TL;DR: After recounting the many problems of knowledge extraction - including a swipe at nanopubs which "are ... dead in my view (without admitting it)" - he concludes: Well worth a read, and much food for thought.
Published today in GigaScience is a Data Note describing the National COVID-19 Chest Imaging Database (NCCID), a centralised database containing chest X-rays, Computed Tomography (CT) and MRI scans from patients across the UK. Utilising the UK National Health Service’s unique position as the world’s single largest integrated healthcare system, the benefits of collecting chest imaging data this large are extensive and already being used

A new article published today in GigaScience demonstrates that machine learning can yield “proxy measures” for brain-related health issues from large population data, without the need for a specialist’s assessment.

Came across Microsoft's announcement of a "A planetary computer for a sustainable future through the power of AI", complete with a glossy video featuring Lucas Joppa @lucasjoppa (see also @Microsoft_Green and #AIforEarth). On the one hand it's great to see super smart people with lots of resources tackling important questions, but it's hard not to escape the feeling that this is the classic technology company approach of framing difficult