Publicados in quantixed
Autor Stephen Royle
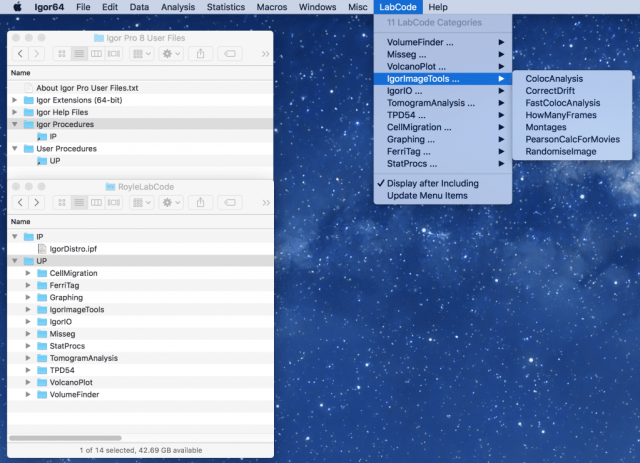
This post is something of a “how to” guide. The problem is how can you share code with a small team and keep it up-to-date? For ImageJ, the solution is simple. You can make an ImageJ update site and then push any updated code to the user when they startup ImageJ. For IgorPro, there is no equivalent. Typically I send ipf files to someone and they run the code, but I have to resend them whenever there’s an update.