Publicados in dataand.me
Autor Mara Averick
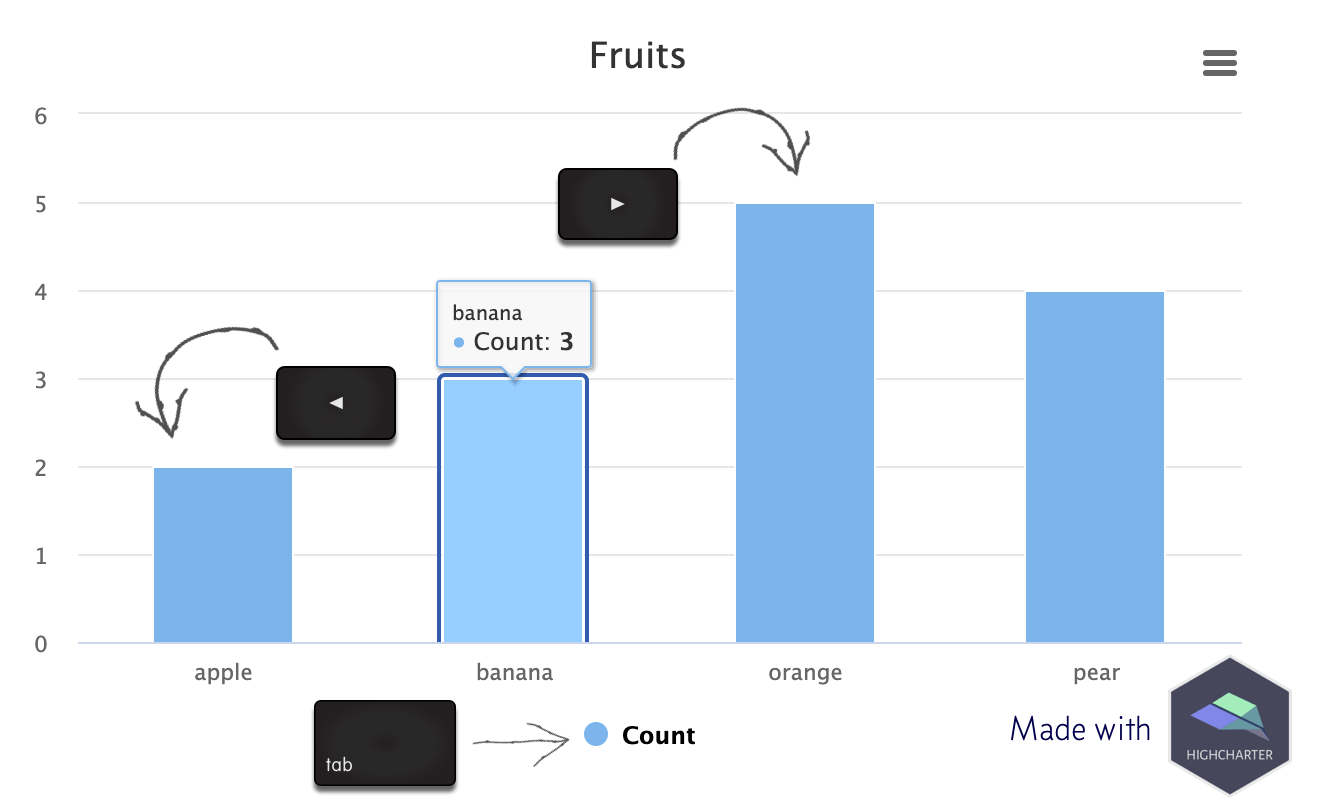
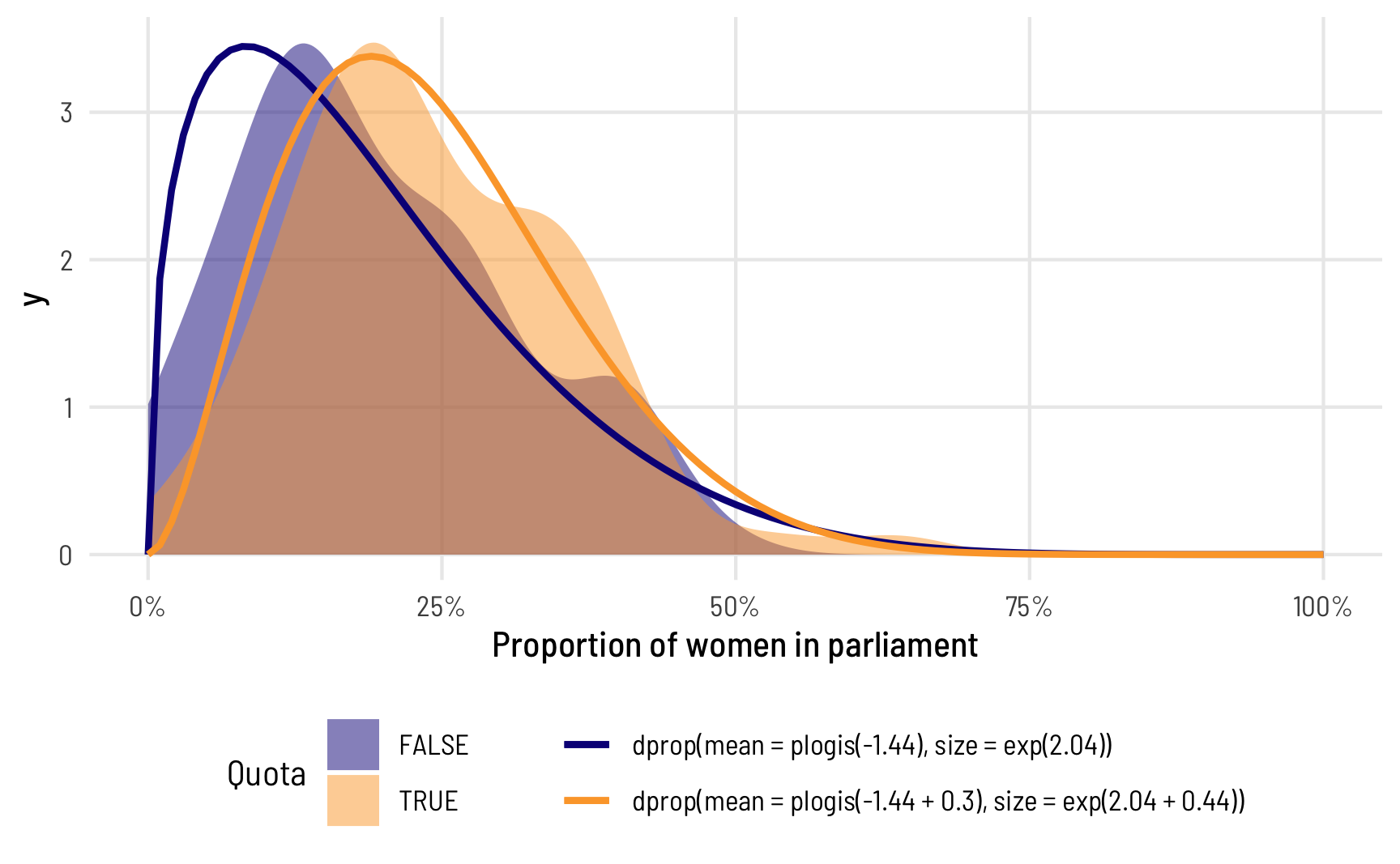
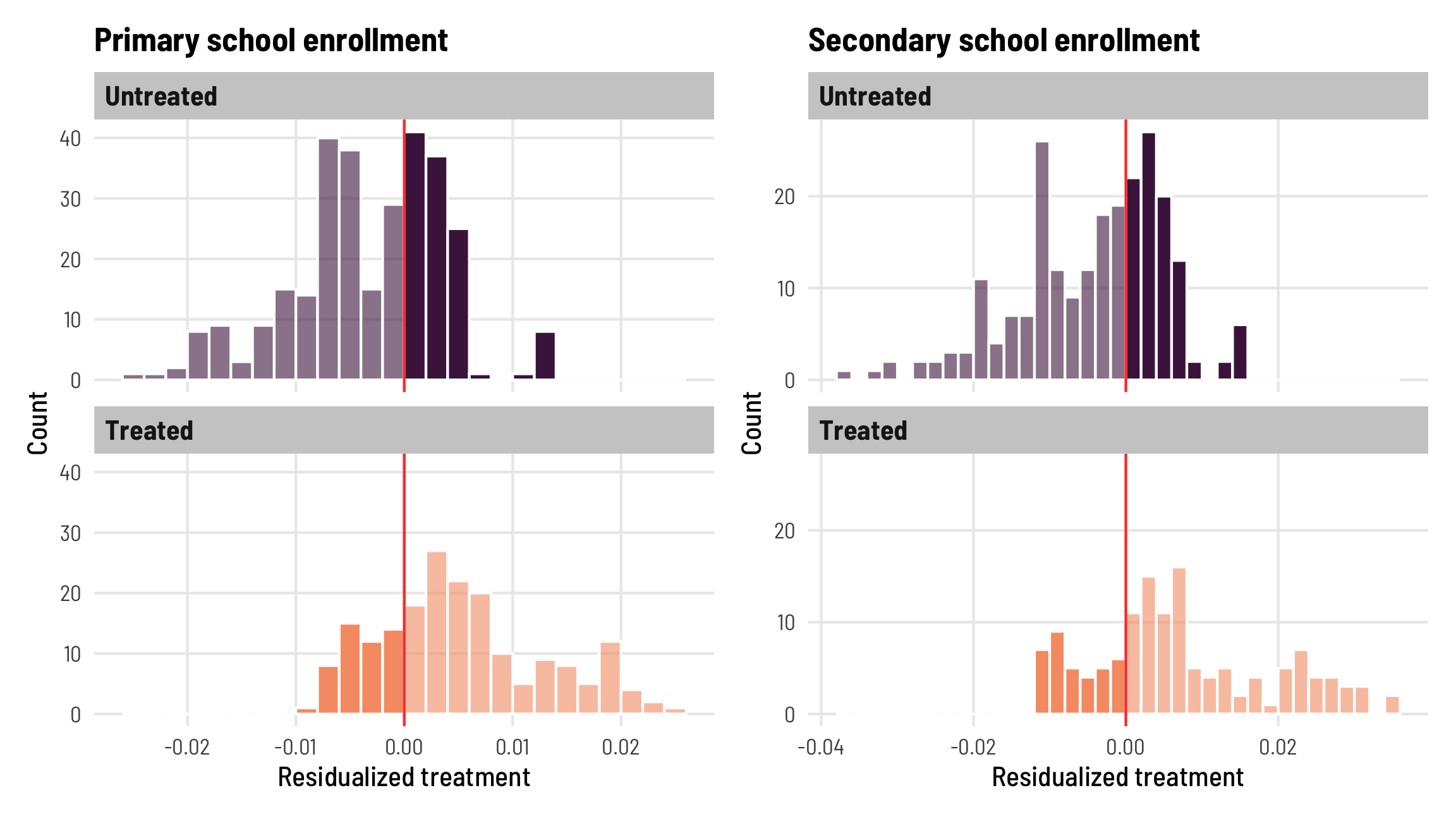
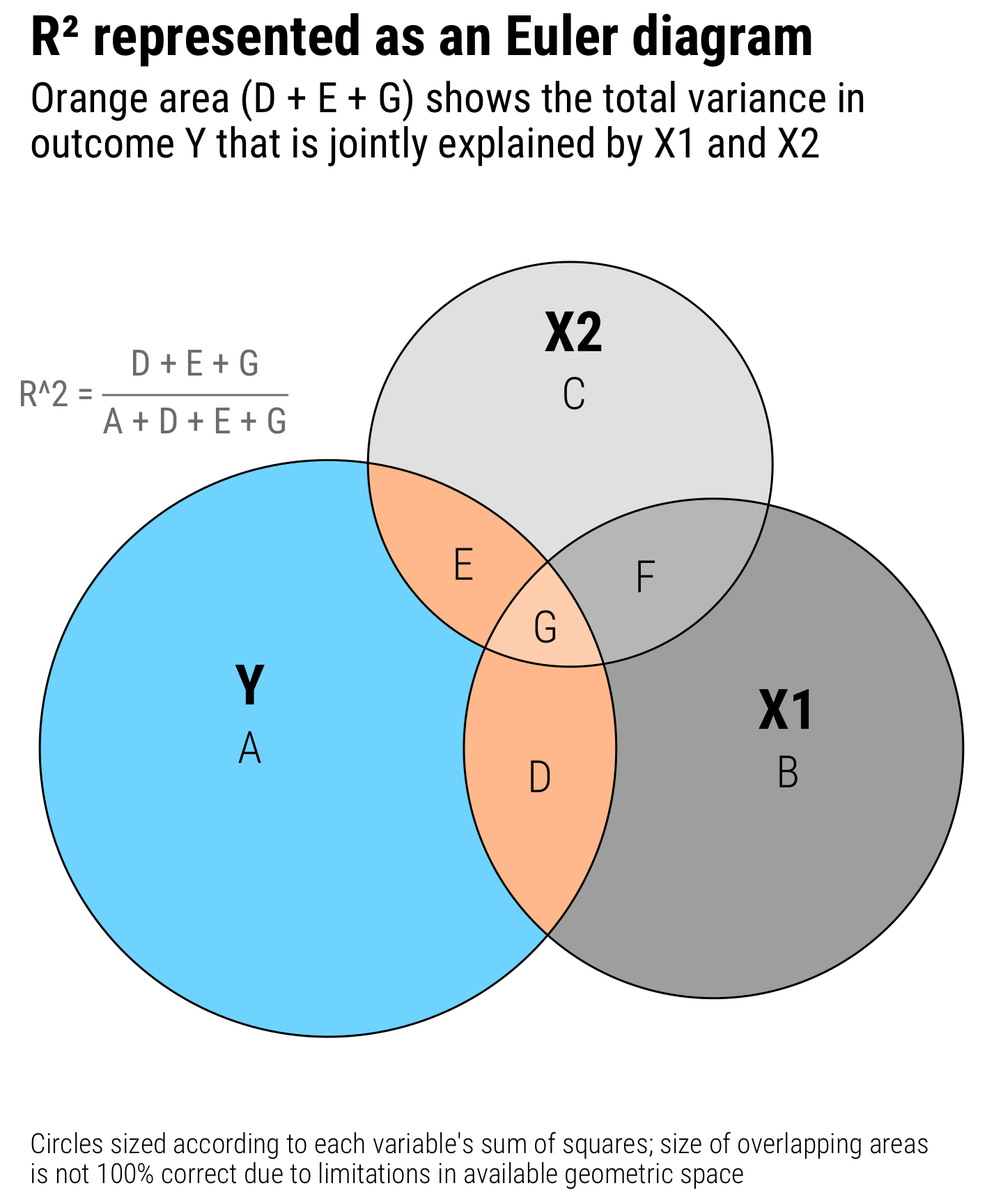
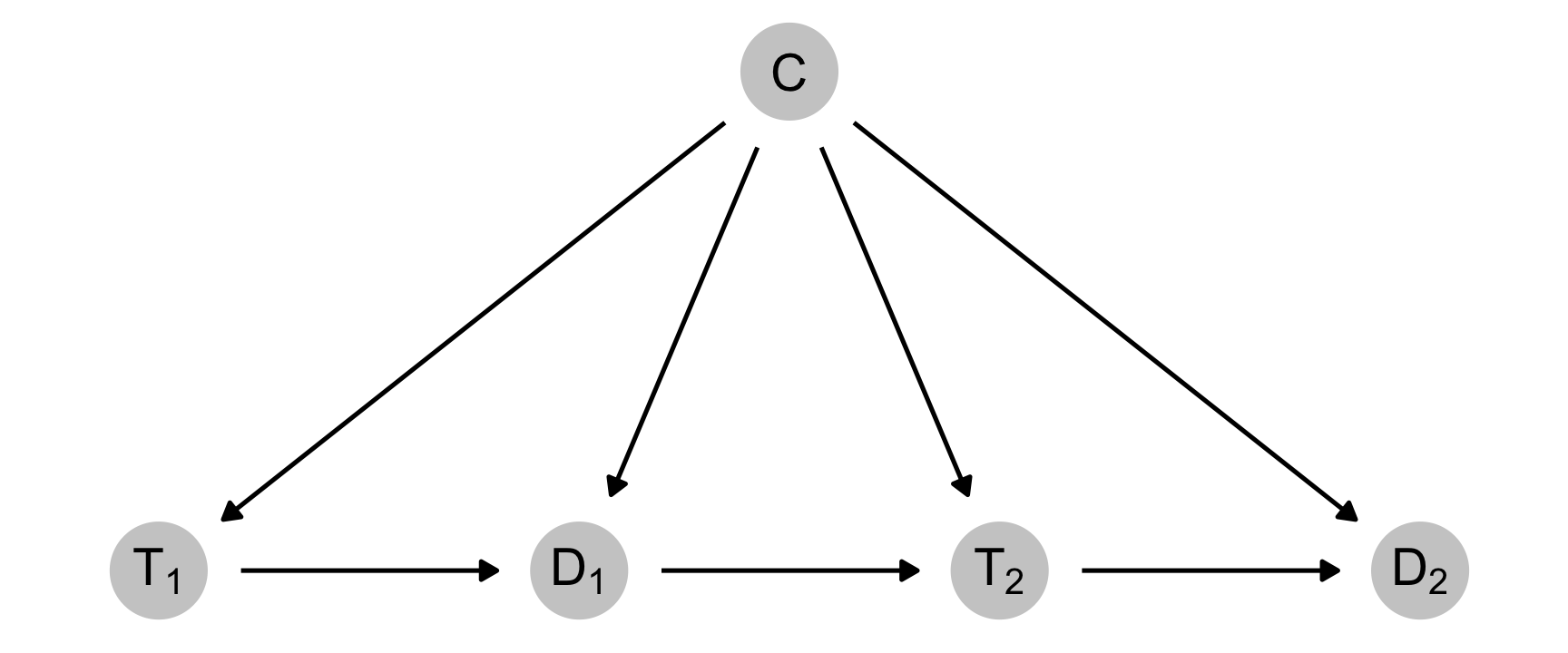
Over the past few weeks I’ve been experimenting with the accessibility module from Highcharts using the {highcharter} package by Joshua Kunst. Highcharts is an SVG-based library for making interactive charts for the web.