Publicados in iPhylo
Autor Roderic Page
There are several instances where I have a collection of references that I want to deduplicate and merge.
There are several instances where I have a collection of references that I want to deduplicate and merge.

Continuing the theme of the failings of the GBIF classification I've been playing further with cluster maps to visualise the problem (see this earlier post for an introduction).Browsing through bats in GBIF I keep finding the same species appearing more than once, albeit in different genera.
Readers of this blog will know that I'm sceptical about the current value of linked data and RDF in biodiversity informatics. But I came across an interesting paper on RDF and biocuration that suggests a good "use case" for RDF in constructing and curating taxonomic databases.The paper is "Catching inconsistencies with the semantic web: a biocuration case study" (PDF here) by Jerven Bolleman and Sebastien Gehant.
Over on Google Plus (yeah, me neither) Donat Agosti is giving me a hard time regarding the quality of some data that I am using.

I know I'm starting to sound like a broken record, but the more I look, the more taxonomic databases seem to be full of garbage. Databases such as the Catalogue of life, which states that it is a "quality-assured checklist" have records that are patently wrong.

This post arose from an ongoing email conversation with Tony Rees about extracting and annotating taxonomic names. In BioStor I use the GBIF classification to display the taxonomic names found in the OCR text in the form of a tree.
Revisiting an old idea (Clustering taxonomic names) I've added code to cluster strings into sets of similar strings to the phyloinformatics course site.This service (available at http://iphylo.org/~rpage/phyloinformatics/services/clusterstrings.php) takes a list of strings, one per line, and returns a list of clusters.

Google Refine is an elegant tool for data cleaning. One of its most powerful features is the ability to call "Reconciliation Services" to help clean data, for example by matching names to external identifiers. Google Refine comes with the ability to use Freebase reconciliation services, but you can also add external services.

One issue I'm running into with Mendeley is that it can create spurious documents, mangling my references in the process. This appears to be due to some over-zealous attempts to de-duplicate documents.
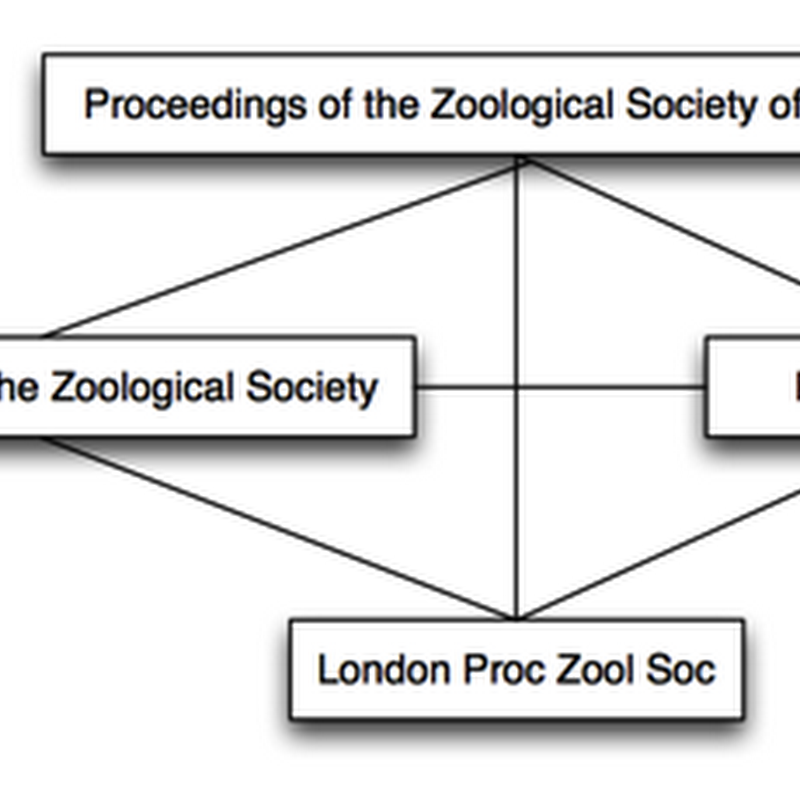
Continuing with my exploration of the Biodiversity Heritage Library one obstacle to linking BHL content with nomenclature databases is the lack of a consistent way to refer to the same bibliographic item (e.g., book or journal). For example, the Amphibia Species of the World (ASW) page for Gastrotheca aureomaculata gives the first reference for this name as: Gastrotheca aureomaculata Cochran and Goin, 1970, Bull. U.S. Natl.