
A Brief Introduction to Retrieval Augmented Generation (RAG)


Authors: Hui Yin , Amir Aryani
With the increasing application of large language models in various scenarios, people realize that these models are not omnipotent. When generating dialogues (Shuster et al., 2021), the models often produce hallucinations, leading to inaccurate answers. Despite these large language models storing impressive knowledge within their parameters of a neural network, these hallucinated facts are frozen at the point of model training, making it infeasible to retrain the model. If we can bootstrap the model correctly, it can still be a powerful tool, and here comes the Retrieval Augmented Generator (RAG).
Retrieval-augmented generation (RAG) is an AI framework designed to enhance the quality of responses generated by large language models (LLM). It leverages external knowledge sources, typically knowledge graphs or other knowledge bases, such as Wikipedia, to augment the generation capabilities of these models. This integration enables the model to incorporate additional external information during text generation, thereby improving its accuracy and applicability while ensuring access to the latest reliable information.
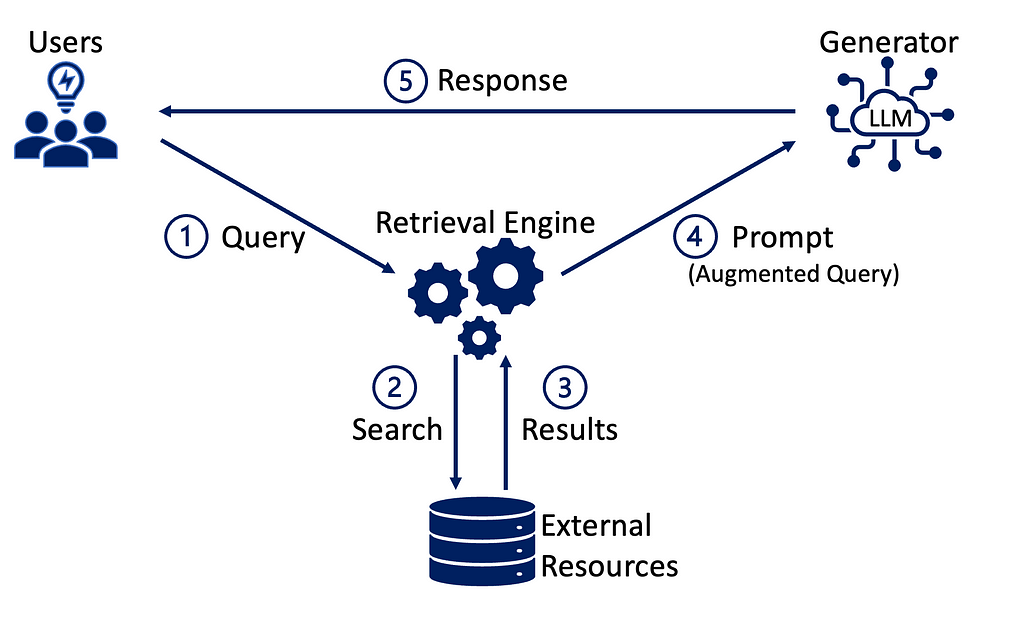
The retrieval-augmented generator (RAG) was initially introduced in "REALM: Retrieval-Augmented Language Model Pretraining" by Guu et al., (2020), where they discuss the utilization of dense retrievers to enhance language model pre-training. In REALM, the retriever accesses knowledge from a textual knowledge corpus, (e.g., all of Wikipedia), and then the signal from the generator backpropagates through the retriever. They verified the effectiveness of the proposed Retrieval-Augmented Language Model pre-training (REALM) on the challenging Open-domain Question Answering (Open-QA) task. The results demonstrated its superiority over three benchmarks by a substantial margin (4–16% absolute accuracy), and it also showcased improvements in interpretability and modularity.
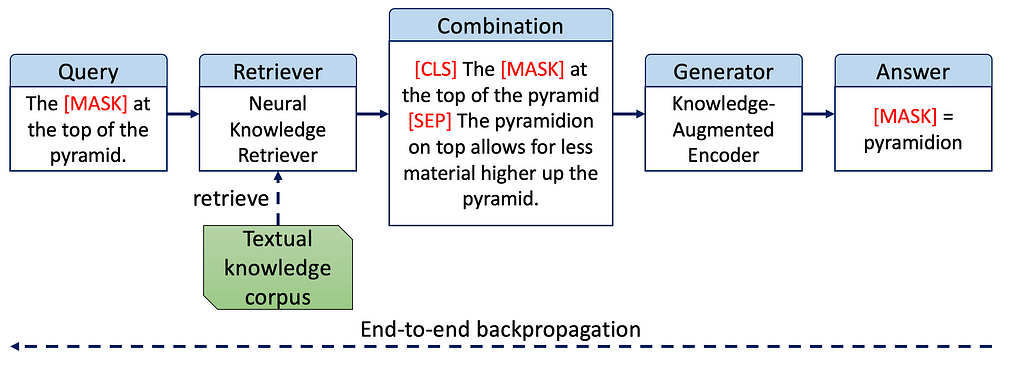
Structure of REALM: BERT is employed to encode queries and documents separately, and Maximum Inner Product Search (MIPS) is utilized to calculate the inner product between query embeddings and document embeddings, identifying the most relevant documents. Subsequently, the concatenated query and selected documents are input into the knowledge-augmented encoder (BERT pre-training) as new input, and the final result is generated.
Another remarkable work is "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" by Lewis et al., (2020). They constructed a pre-trained retriever consisting of a Query encoder and a Document index. For example, Maximum Inner Product Search (MIPS) was employed to identify the top-K documents. The generator component of the system was a pre-trained seq2seq model. The entire model was fine-tuned end-to-end. In their approach for final predictions, they treated k (the number of documents selected by the retriever) as a latent variable. This allowed them to control the number of outputs predicted by the seq2seq model.
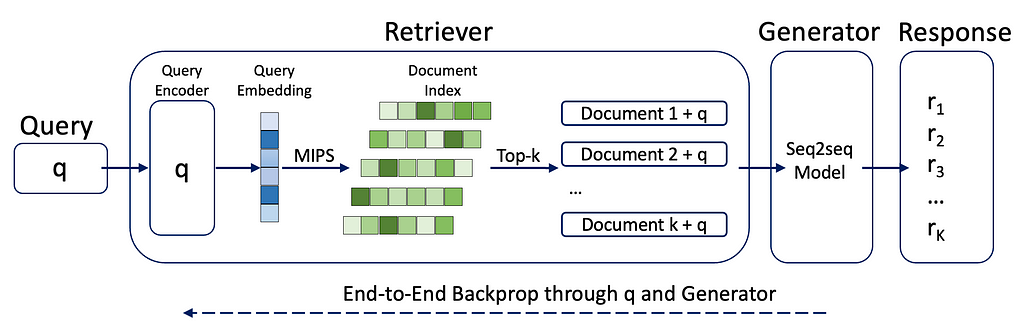
Overview of the structure: The retriever combines QueryEncoder and Document Index, and the generator consists of a pre-trained seq2seq model fine-tuned end-to-end. Maximum Inner Product Search (MIPS) is utilized to find the top-k similar documents. For the final predictions, 'k' acts as a latent variable, and marginalises over seq2seq predictions given different documents.
The above two works have inspired more researchers to study RAG. Based on the basic structure shown in the first figure, specific implementation methods are shown in other works. These existing works all demonstrate RAG's contribution to LLM in the following aspects:
- Utilisation of the latest external knowledge,
- Flexibility and adaptability,
- Quality improvement,
- Interpretability,
- Modularity, and
- Model size reduction.
From an application perspective, the original RAG was oriented to NLP tasks such as Open-QA (Mao et al., 2020) and dialogue (Thulke et al., 2021) and is now also used for image synthesis (Blattmann et al., 2022) and text-to-image (Chen et al., 2022).
RAG possesses many advantages; however, it's crucial to acknowledge that leveraging an external document database to enhance the generation process involves computing the similarity between the query embedding and external document embeddings, followed by selecting the top-k documents. This introduces substantial computational challenges. As the size of the external document database increases, the computational cost of calculating similarity and determining the top-k documents grows significantly. Achieving scalability, especially when processing numerous documents, demands efficient algorithms and parallel processing capabilities to make the retrieval process feasible within a reasonable timeframe. Additionally, storing and accessing large external databases can necessitate significant memory resources. For applications requiring real-time responses, the time taken for retrieval becomes a critical factor, emphasizing the need to balance computational complexity with response time. Hence, delving into optimization and approximation methods or incorporating specialized hardware emerges as promising avenues for future research.
As an auxiliary to LLM, it is foreseeable that more people will devote their energy to exploring various applications of RAG.
Acknowledgement
This work was supported by the Australian Government through the Australian Research Council's Industrial Transformation Training Centre for Information Resilience (CIRES) project number IC200100022.
Shuster, K., Poff, S., Chen, M., Kiela, D., & Weston, J. (2021). Retrieval augmentation reduces hallucination in conversation. https://arxiv.org/abs/2104.07567
Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M. (2020). Retrieval Augmented Language Model Pre-Training. In Proceedings of the 37th International Conference on Machine Learning, PMLR (Vol. 119, pp. 3929–3938). Available from https://proceedings.mlr.press/v119/guu20a.html
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., & Kiela, D. (2020b). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Neural Information Processing Systems 33 (NeurIPS 2020). https://arxiv.org/abs/2005.11401
Mao, Y., He, P., Liu, X., Shen, Y., Gao, J., Han, J., & Chen, W. (2020). Generation-Augmented Retrieval for Open-domain Question Answering. https://doi.org/10.48550/arXiv.2009.08553
Thulke, D., Daheim, N., Dugast, C., & Ney, H. (2021). Efficient Retrieval Augmented Generation from Unstructured Knowledge for Task-Oriented Dialog. Accepted by DSTC9 Workshop at AAAI-2021. https://doi.org/10.48550/arXiv.2102.04643
Blattmann, A., Rombach, R., Oktay, K., Müller, J., & Ommer, B. (2022). Retrieval-Augmented Diffusion Models. In Advances in Neural Information Processing Systems 35 (NeurIPS 2022) . https://doi.org/10.48550/arXiv.2204.11824
Chen, W., Hu, H., Chen, X., Verga, P., & Cohen, W. W. (2022). MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text. Accepted to EMNLP 2022 main conference. https://doi.org/10.48550/arXiv.2210.02928
Additional details
Description
Authors: Hui Yin , Amir Aryani With the increasing application of large language models in various scenarios, people realize that these models are not omnipotent. When generating dialogues (Shuster et al., 2021), the models often produce hallucinations, leading to inaccurate answers.
Identifiers
- UUID
- 2106a36c-ebc8-49ac-baa1-b33ff14a2d00
- GUID
- https://medium.com/p/4bd6e50da532
- URL
- https://medium.com/@amiraryani/a-brief-introduction-to-retrieval-augmented-generation-rag-4bd6e50da532
Dates
- Issued
-
2024-01-18T02:57:53
- Updated
-
2024-01-18T02:57:53